





Arquivos de Comprimento Fixo com Spring Batch 6.0: O “Prazer” dos Dados Legados
Se você é um desenvolvedor que já lidou com processamento de folha de pagamento ou conciliação bancária/financeira em uma empresa que usa Spring, provavelmente já trabalhou com Spring Batch. Confesso que não sou um grande fã; ele tem aquela característica verbosidade e sobrecarga do ecossistema Java, fazendo parecer que até o job mais simples exige muito mais estrutura do que o necessário. Mas de que adianta reclamar? A tecnologia que sua empresa usa é o que garante sua sobrevivência (moradia, comida, roupa). Então, lamentações não são o tema de hoje.
O escopo deste post é extremamente simples: dado um arquivo posicional gerado via mainframe usando o template abaixo, criaremos uma aplicação Spring Batch (usando a versão 6.0, a mais recente até hoje) para ler facilmente o arquivo, criar um objeto e exibir o conteúdo no console em formato JSON. A parte chave aqui é a leitura do arquivo e sua transformação em um objeto Java padrão. Quanto à etapa de escrita, você pode lidar como quiser: salvar em um banco de dados, escrever em outro arquivo, o que diabos você quiser fazer.
Para isso, consideraremos o template abaixo:
| CAMPO | INÍCIO | FIM | COMPRIMENTO | FORMATO (COBOL PIC) | TIPO DE DADO | DESCRIÇÃO |
|---|---|---|---|---|---|---|
| COMIC-TITLE | 01 | 30 | 30 | PIC X(30) | ALFANUMÉRICO | O título da revista em quadrinhos. Alinhado à esquerda, preenchido com espaços. |
| ISSUE-NUM | 31 | 35 | 05 | PIC 9(05) | NUMÉRICO (ZONADO) | O número sequencial da edição. Alinhado à direita, preenchido com zeros. |
| PUBLISHER | 36 | 55 | 20 | PIC X(20) | ALFANUMÉRICO | O nome da editora. Alinhado à esquerda, preenchido com espaços. |
| PUB-DATE | 56 | 65 | 10 | PIC X(10) | DATA (ISO) | Data de publicação no formato YYYY-MM-DD. Tratado como texto. |
| CVR-PRICE | 66 | 72 | 07 | PIC 9(07) | NUMÉRICO (ZONADO) | Preço de capa. Alinhado à direita, preenchido com zeros. Nota: O tratamento decimal depende da lógica de parsing. |
E vamos supor que estamos recebendo o arquivo abaixo na plataforma distribuída. Note que ao lidar com formatos numéricos (PIC 9), preenchemos o campo com zeros à esquerda, e para campos alfanuméricos (PIC X), preenchemos o comprimento fixo com espaços à direita.
Action Comics 00001DC Comics 1938-04-180000.10
Detective Comics 00027DC Comics 1939-03-300000.10
Batman 00001DC Comics 1940-04-240000.10
Superman 00001DC Comics 1939-05-180000.10
Wonder Woman 00001DC Comics 1942-07-220000.10
Flash Comics 00001DC Comics 1940-01-010000.10
Green Lantern 00001DC Comics 1941-07-010000.10
Amazing Fantasy 00015Marvel 1962-08-100000.12
The Incredible Hulk 00001Marvel 1962-05-010000.12
Fantastic Four 00001Marvel 1961-11-010000.10
Journey into Mystery 00083Marvel 1962-08-010000.12
Tales of Suspense 00039Marvel 1963-03-010000.12
The X-Men 00001Marvel 1963-09-010000.12
The Avengers 00001Marvel 1963-09-010000.12
Daredevil 00001Marvel 1964-04-010000.12
Showcase 00004DC Comics 1956-09-010000.10
Justice League of America 00001DC Comics 1960-10-010000.10
The Brave and the Bold 00028DC Comics 1960-02-010000.10
Swamp Thing 00001DC Comics 1972-10-010000.20
Giant-Size X-Men 00001Marvel 1975-05-010000.50
Crisis on Infinite Earths 00001DC Comics 1985-04-010000.75
Watchmen 00001DC Comics 1986-09-010001.50
The Dark Knight Returns 00001DC Comics 1986-02-010002.95
Maus 00001Pantheon 1986-01-010003.50
Sandman 00001Vertigo 1989-01-010001.50
Spawn 00001Image Comics 1992-05-010001.95
Savage Dragon 00001Image Comics 1992-06-010001.95
WildC.A.T.s 00001Image Comics 1992-08-010001.95
Youngblood 00001Image Comics 1992-04-010002.50
Hellboy: Seed of Destruction 00001Dark Horse 1994-03-010002.50
Sin City 00001Dark Horse 1991-04-010002.25
Preacher 00001Vertigo 1995-04-010002.50
The Walking Dead 00001Image Comics 2003-10-010002.99
Invincible 00001Image Comics 2003-01-010002.99
Saga 00001Image Comics 2012-03-140002.99
Paper Girls 00001Image Comics 2015-10-070002.99
Monstress 00001Image Comics 2015-11-040004.99
Descender 00001Image Comics 2015-03-040002.99
East of West 00001Image Comics 2013-03-270003.50
Ms. Marvel 00001Marvel 2014-02-010002.99
Miles Morales: Spider-Man 00001Marvel 2018-12-120003.99
House of X 00001Marvel 2019-07-240005.99
Powers of X 00001Marvel 2019-07-310005.99
Batman: Court of Owls 00001DC Comics 2011-09-210002.99
Doomsday Clock 00001DC Comics 2017-11-220004.99
Immortal Hulk 00001Marvel 2018-06-060004.99
Something is Killing Child 00001BOOM! Studios 2019-09-040003.99
Department of Truth 00001Image Comics 2020-09-300003.99
Nice House on the Lake 00001DC Black Label 2021-06-010003.99
Ultimate Spider-Man 00001Marvel 2024-01-100005.99
Vamos começar.
1. Configuração inicial que todo dev Java odeia
Para acelerar a criação da base, configurei um projeto usando o spring initializr. Basicamente, criei um projeto Spring Boot com Maven, Java 21 e Spring Boot 4.0.0. Sim, criei sem nenhuma dependência, pois editarei manualmente o pom.xml. Acredito que o Spring Boot 4.0 já venha com Spring Batch 6 (se adicionado como dependência), mas, honestamente, há coisas que prefiro ajustar manualmente.
Com o projeto criado, vamos construir nosso pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>4.0.0</version>
<relativePath/>
</parent>
<groupId>me.doismiu</groupId>
<artifactId>spring-batch-bean-io</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>spring-batch-bean-io</name>
<description>Spring Batch 6 BeanIO Example</description>
<properties>
<java.version>21</java.version>
<spring-batch.version>6.0.0</spring-batch.version>
<spring-framework.version>7.0.0</spring-framework.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.beanio</groupId>
<artifactId>beanio</artifactId>
<version>2.1.0</version>
<exclusions>
<exclusion>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-core</artifactId>
</exclusion>
<exclusion>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-infrastructure</artifactId>
</exclusion>
<exclusion>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jsr310</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
<pluginRepository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</pluginRepository>
</pluginRepositories>
</project>
Como você deve ter notado, trabalharemos com as seguintes libs neste projeto:
Spring Batch 6.0
Spring Boot 4.0.0
Spring Boot Starter JDBC. Como temos que configurar o
TransactionManagerpara a conexão com o banco de dados, precisaremos desta lib.BeanIO 2.1.0. A lib que realiza a mágica de converter campos posicionais em atributos de objeto; além disso, vem com uma série de classes especiais para Spring Batch!
Libs Jackson para converter facilmente o objeto em uma estrutura JSON em nosso Writer.
Agora, criaremos nossa estrutura Main e a conexão com o banco de dados. Aqui vemos a primeira grande mudança no Spring Batch 6: a chamada "Infraestrutura de batch sem recursos por padrão". Quem já trabalhou com Spring Batch sabe que era quase sempre necessário vincular o Batch a um banco de dados, pois essa tecnologia armazena metadados para execuções de Job e Step, que são de extrema importância para o controle de execução. No entanto, na versão mais recente, o Batch não precisa estar vinculado a nenhum banco de dados por padrão. Como mencionei, como isso é importante, vamos configurá-lo mesmo assim. Em nosso cenário, o batch requer a estrutura abaixo para rodar:
Neste projeto, usei PostgreSQL via Docker para facilitar as coisas, mas deve funcionar com qualquer banco de dados, até mesmo NoSQL como MongoDB. Para isso, criei o seguinte docker compose.
version: '3.8'
services:
postgres:
image: postgres:15-alpine
container_name: comic_postgres
environment:
POSTGRES_USER: user
POSTGRES_PASSWORD: password
POSTGRES_DB: comicbatch
ports:
- "5432:5432"
volumes:
- postgres_data:/var/lib/postgresql/data
volumes:
postgres_data:
Mas como disse, qualquer banco de dados serve. Após subir o docker compose, teremos um container chamado comic_postgres rodando em nosso Docker local. Com isso, podemos prosseguir para configurar nosso arquivo application.properties do projeto.
spring.application.name=spring-batch-bean-io
spring.datasource.url=jdbc:postgresql://localhost:5432/comicbatch
spring.datasource.username=user
spring.datasource.password=password
spring.datasource.driver-class-name=org.postgresql.Driver
logging.level.org.springframework.jdbc.core=DEBUG
logging.level.org.springframework.transaction=DEBUG
spring.batch.jdbc.initialize-schema=never
Aqui configurei o JDBC para não criar tabelas na inicialização. TEORICAMENTE, o Batch deveria criar a estrutura de metadados sem problemas, mas admito que usei extensivamente as versões 4 e 5 do Spring Batch, e ele NUNCA criou a estrutura corretamente. Isso leva a erros em tempo de execução da aplicação, muito provavelmente devido a colunas ausentes ou tipagem incorreta. Ainda pior seria pegar algum script aleatório da internet e criar as tabelas diretamente no banco de dados. Em vez disso, temos uma solução que lê a estrutura correta fornecida pela própria biblioteca e adapta-a ao tipo de banco de dados que estamos usando. Aqui está como nossa classe Main fica, implementando essa lógica de banco de dados:
package me.doismiu.fixedlength;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.core.io.ClassPathResource;
import org.springframework.jdbc.datasource.init.DataSourceInitializer;
import org.springframework.jdbc.datasource.init.ResourceDatabasePopulator;
import javax.sql.DataSource;
@SpringBootApplication
public class ComicBatchApplication {
public static void main(String[] args) {
System.exit(
SpringApplication.exit(
SpringApplication.run(ComicBatchApplication.class, args)));
}
@Bean
public DataSourceInitializer databaseInitializer(DataSource dataSource) {
ResourceDatabasePopulator populator = new ResourceDatabasePopulator();
populator.addScript(new ClassPathResource("org/springframework/batch/core/schema-postgresql.sql"));
populator.setContinueOnError(true);
DataSourceInitializer initializer = new DataSourceInitializer();
initializer.setDataSource(dataSource);
initializer.setDatabasePopulator(populator);
return initializer;
}
}
Isso garante que na primeira execução do Batch, ele cria a estrutura adequada esperada pelo framework, já que o arquivo de criação é fornecido pelo próprio Spring Batch. Note que também incluí a linha populator.setContinueOnError(true). Isso significa que sempre que houver um erro de estrutura SQL, ele será ignorado, dado que este script será executado a cada execução do Batch. Existem maneiras mais elegantes de lidar com isso, ou você poderia até remover este método após a primeira execução se preferir. Mas para nosso exemplo, funciona perfeitamente.
Vamos aproveitar para finalizar a configuração do banco de dados criando uma classe vazia, mas com anotações especificando a configuração do TransactionManager:
package me.doismiu.fixedlength.config;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.EnableJdbcJobRepository;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.annotation.Isolation;
@Configuration
@EnableBatchProcessing
@EnableJdbcJobRepository(dataSourceRef = "dataSource", transactionManagerRef = "transactionManager", isolationLevelForCreate = Isolation.READ_COMMITTED, tablePrefix = "BATCH_")
public class JDBCJobRepositoryConfig {
}
2. O objeto com anotações BeanIO
Para este projeto, precisamos criar um modelo chamado Comic contendo as informações do template posicional que mostrei no início do post. Podemos fazer isso via XML ou via anotação, é uma questão de gosto pessoal. No exemplo deste projeto, usarei a versão com anotação, pois sinto que organiza a estrutura de um template posicional de forma mais simples.
package me.doismiu.fixedlength.model;
import org.beanio.annotation.Field;
import org.beanio.annotation.Record;
import org.beanio.builder.Align;
import java.math.BigDecimal;
import java.time.LocalDate;
@Record
public class Comic {
@Field(at = 0, length = 30, padding = ' ', align = Align.LEFT)
private String title;
@Field(at = 30, length = 5, padding = '0', align = Align.RIGHT)
private int issueNumber;
@Field(at = 35, length = 20, padding = ' ', align = Align.LEFT)
private String publisher;
@Field(at = 55, length = 10, format = "yyyy-MM-dd")
private LocalDate publicationDate;
@Field(at = 65, length = 7, padding = '0', align = Align.RIGHT)
private BigDecimal coverPrice;
// Getters and Setters
}
Sobre o modelo, alguns pontos merecem destaque:
Os atributos não precisam necessariamente estar na ordem do template, mas recomendo fortemente mantê-los assim para facilitar a manutenção do código.
Usamos a lógica padding + align para preencher com zeros à esquerda ou espaços à direita, conforme estipulado no layout do arquivo. Além disso, informamos ao BeanIO que o campo de data esperado tem um formato definido. Falaremos mais sobre isso ao escrever o Reader da aplicação.
E é isso, simples assim. Agora vamos para a criação do nosso Reader e Writer.
3. Um Reader que justifica a existência deste post, um Writer que faz o que diabos quiser
Normalmente, a lógica do Batch dita criar uma aplicação na seguinte ordem: Job -> Step -> Reader/Processor/Writer. Mas como cada peça depende da última, começaremos do final.
Em nosso Reader, usaremos o melhor que o BeanIO oferece para Batches. Criaremos nossa lógica de leitura de arquivo usando o StreamBuilder padrão da biblioteca. Também usaremos a própria lógica de Skip do BeanIO para evitar reler entradas do banco de dados ao retomar um serviço que foi interrompido. Para que isso funcione, em vez de usar o FileFlatItemReader padrão do Batch, usaremos o AbstractItemCountingItemStreamItemReader. Isso nos permite retomar qualquer processo de leitura que foi interrompido, combinado com a lógica JumpItem que criamos com o BeanIO. Basicamente, configuraremos o StreamBuilder no construtor da classe e trataremos a abertura e fechamento de streams adequadamente. Isso nos dá o seguinte reader:
package me.doismiu.fixedlength.reader;
import me.doismiu.fixedlength.handler.LocalDateTypeHandler;
import me.doismiu.fixedlength.model.Comic;
import org.beanio.BeanReader;
import org.beanio.StreamFactory;
import org.beanio.builder.FixedLengthParserBuilder;
import org.beanio.builder.StreamBuilder;
import org.springframework.batch.infrastructure.item.ItemStreamException;
import org.springframework.batch.infrastructure.item.support.AbstractItemCountingItemStreamItemReader;
import org.springframework.core.io.Resource;
import org.springframework.util.Assert;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
import java.time.LocalDate;
public class ComicItemsReader extends AbstractItemCountingItemStreamItemReader<Comic> {
private final Resource resource;
private final StreamFactory streamFactory;
private BeanReader beanReader;
public ComicItemsReader(Resource resource) {
this.resource = resource;
setName("comicItemsReader");
this.streamFactory = StreamFactory.newInstance();
StreamBuilder builder = new StreamBuilder("comicStream")
.format("fixedlength")
.parser(new FixedLengthParserBuilder())
.addTypeHandler(LocalDate.class, new LocalDateTypeHandler("yyyy-MM-dd"))
.addRecord(Comic.class);
this.streamFactory.define(builder);
}
@Override
protected void jumpToItem(int itemIndex) throws Exception {
if (beanReader != null) {
beanReader.skip(itemIndex);
}
}
@Override
protected void doOpen() throws Exception {
Assert.notNull(resource, "Input resource must be set");
if (!resource.exists()) {
throw new ItemStreamException("Input resource does not exist: " + resource);
}
this.beanReader = streamFactory.createReader(
"comicStream",
new InputStreamReader(resource.getInputStream(), StandardCharsets.UTF_8));
}
@Override
protected Comic doRead() throws Exception {
if (beanReader == null) {
return null;
}
return (Comic) beanReader.read();
}
@Override
protected void doClose() throws Exception {
if (beanReader != null) {
beanReader.close();
beanReader = null;
}
}
}
Note que ao implementar esta classe, o compilador sinalizará um erro na seguinte linha:
.addTypeHandler(LocalDate.class, new LocalDateTypeHandler("yyyy-MM-dd"))
Isso ocorre porque ainda não criamos o LocalDateTypeHandler. E por que precisamos de um handler específico para datas? Em uma aplicação de exemplo, eu poderia ignorar um atributo LocalDate e tratar tudo como Strings e Ints. Mas como disse, um dos principais tipos de arquivos processados em batches está relacionado a pagamentos. E pagamentos têm datas. Queremos poder manipular esse atributo como uma data. Se executarmos o reader sem nossa lógica TypeHandler, obteremos o seguinte erro:
org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'importComicJob' defined in class path resource [me/doismiu/fixedlength/job/ComicPrinterJob.class]: Unsatisfied dependency expressed through method 'importComicJob' parameter 1: Error creating bean with name 'printStep' defined in class path resource [me/doismiu/fixedlength/step/ComicPrinterStep.class]: Unsatisfied dependency expressed through method 'printStep' parameter 2: Error creating bean with name 'comicItemsReader' defined in class path resource [me/doismiu/fixedlength/step/ComicPrinterStep.class]: Failed to instantiate [me.doismiu.fixedlength.reader.ComicItemsReader]: Factory method 'comicItemsReader' threw exception with message: Invalid field 'publicationDate', in record 'comic', in stream 'comicStream': Type handler not found for type 'java.time.LocalDate'
Em resumo: o BeanIO não fornece um TypeHandler padrão para LocalDate com o formato que queremos. É por isso que criaremos uma classe para resolver isso.
package me.doismiu.fixedlength.handler;
import org.beanio.types.ConfigurableTypeHandler;
import org.beanio.types.TypeHandler;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.util.Properties;
public class LocalDateTypeHandler implements ConfigurableTypeHandler {
private final DateTimeFormatter formatter;
public LocalDateTypeHandler(String pattern) {
this.formatter = DateTimeFormatter.ofPattern(pattern);
}
@Override
public TypeHandler newInstance(Properties properties) throws IllegalArgumentException {
String format = properties.getProperty("format");
if (format == null || format.isEmpty()) {
return this;
}
return new LocalDateTypeHandler(format);
}
@Override
public Object parse(String text) {
if (text == null || text.trim().isEmpty()) {
return null;
}
return LocalDate.parse(text, formatter);
}
@Override
public String format(Object value) {
if (value == null) {
return null;
}
return ((LocalDate) value).format(formatter);
}
@Override
public Class<?> getType() {
return LocalDate.class;
}
}
Basicamente, estamos registrando nosso tipo de formato personalizado, simples assim. Agora finalmente temos nosso LocalDateTypeHandler criado e vinculado ao nosso Reader. É fácil assim.
Para nosso Writer, conforme especificado, o escopo deste projeto é apenas mostrar a saída do arquivo no console como JSON para provar que estamos usando Objetos reais. Aqui, simplesmente implementar ItemWriter é suficiente. Mas você pode fazer o que quiser com os dados; é com você. Não vou me alongar mais no Writer.
package me.doismiu.fixedlength.writer;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.SerializationFeature;
import com.fasterxml.jackson.datatype.jsr310.JavaTimeModule;
import me.doismiu.fixedlength.model.Comic;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.infrastructure.item.Chunk;
import org.springframework.batch.infrastructure.item.ItemWriter;
import org.springframework.stereotype.Component;
import java.util.List;
@Component
public class ComicPrinterWriter implements ItemWriter<Comic> {
private static final Logger LOGGER = LoggerFactory.getLogger(ComicPrinterWriter.class);
private final ObjectMapper objectMapper;
public ComicPrinterWriter() {
this.objectMapper = new ObjectMapper();
this.objectMapper.registerModule(new JavaTimeModule());
this.objectMapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
this.objectMapper.enable(SerializationFeature.INDENT_OUTPUT);
}
@Override
public void write(Chunk<? extends Comic> chunk) throws Exception {
LOGGER.info("--- Writing Batch of {} items as JSON ---", chunk.size());
List<? extends Comic> items = chunk.getItems();
String jsonOutput = objectMapper.writeValueAsString(items);
System.out.println(jsonOutput);
}
}
4. O Job e Step faltantes para finalizar o projeto
Com o Reader e Writer criados, geramos o Step que orquestrará ambos. Nada complexo aqui, apenas um Step padrão com algum tratamento de falhas e onde especificamos o Resource para nosso arquivo TXT. Se você estiver usando este exemplo para Produção, o tratamento deve ser mais específico, assim como a lógica para retornar corretamente o código de saída da aplicação. Mas para nosso exemplo, o código abaixo funciona:
package me.doismiu.fixedlength.step;
import me.doismiu.fixedlength.model.Comic;
import me.doismiu.fixedlength.reader.ComicItemsReader;
import me.doismiu.fixedlength.writer.ComicPrinterWriter;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.Step;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.FileSystemResource;
import org.springframework.transaction.PlatformTransactionManager;
@Configuration
public class ComicPrinterStep {
@Value("${input.file.path:data/comics.txt}")
private String inputFilePath;
@Bean
public ComicItemsReader comicItemsReader() {
return new ComicItemsReader(new FileSystemResource(inputFilePath));
}
@Bean
public Step printStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager,
ComicItemsReader reader,
ComicPrinterWriter writer) {
return new StepBuilder("comicPrinterStep", jobRepository)
.<Comic, Comic>chunk(10)
.transactionManager(transactionManager)
.reader(reader)
.writer(writer)
.faultTolerant()
.skipLimit(1)
.skip(IllegalArgumentException.class)
.build();
}
}
E com isso, criamos nosso Job.
package me.doismiu.fixedlength.job;
import org.springframework.batch.core.configuration.annotation.EnableJdbcJobRepository;
import org.springframework.batch.core.job.Job;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.job.parameters.RunIdIncrementer;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.Step;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.annotation.Isolation;
@Configuration
public class ComicPrinterJob {
@Bean
public Job importComicJob(JobRepository jobRepository, Step printStep) {
return new JobBuilder("importComicJob", jobRepository)
.incrementer(new RunIdIncrementer())
.start(printStep)
.build();
}
}
E com isso, criamos nosso Job.Com isso, temos toda a estrutura configurada.
5. Testando o que precisa ser testado
Agora estamos prontos para executar nossa aplicação final.
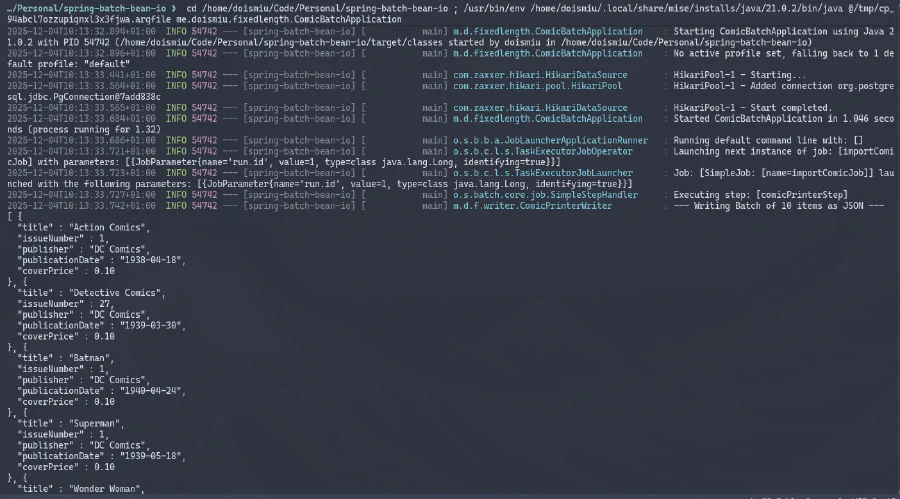
Podemos observar o JSON gerado no console e a conexão com o banco de dados estabelecida com sucesso. E como criamos uma estrutura de metadados para controlar a execução, podemos ir diretamente ao banco de dados para verificar os detalhes da execução:
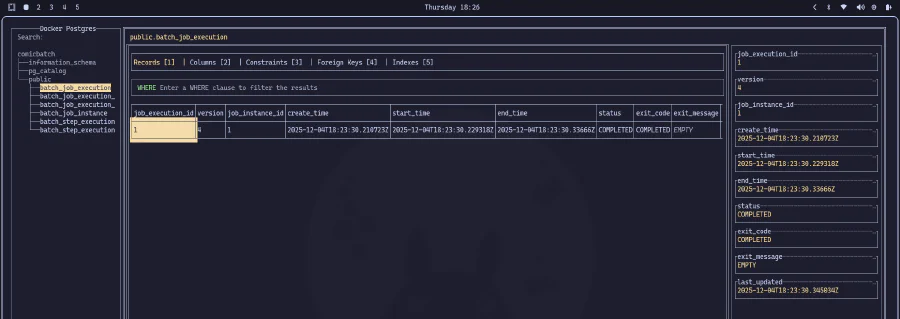
GRANDE SUCESSO!
6. Conclusão
Com isso, agora temos a lógica básica para leitura de arquivos posicionais de largura fixa. Não é nada complexo, mas como este blog visa ser um backup do meu conhecimento, pelo menos estou deixando um registro aqui para não esquecer novamente.

Até a próxima!
