





File a Lunghezza Fissa con Spring Batch 6.0: La “Gioia” dei Dati Legacy
Se sei uno sviluppatore che ha gestito elaborazione di buste paga o riconciliazione bancaria/finanziaria in un’azienda che utilizza Spring, probabilmente hai lavorato con Spring Batch. Confesso di non esserne un grande fan; ha quella caratteristica verbosità e overhead dell’ecosistema Java, che fa sembrare che anche il lavoro più semplice richieda molta più struttura del necessario. Ma a cosa serve lamentarsi? La tecnologia che la tua azienda utilizza è ciò che garantisce la tua sopravvivenza (casa, cibo, vestiti). Quindi, lamentarsi non è l’argomento di oggi.
L’ambito di questo post è estremamente semplice: dato un file posizionale generato tramite un mainframe utilizzando il template qui sotto, creeremo un’applicazione Spring Batch (utilizzando la versione 6.0, la più recente ad oggi) per leggere facilmente il file, creare un oggetto e stampare il contenuto in console in formato JSON. La parte chiave qui è leggere il file e trasformarlo in un oggetto Java standard. Per quanto riguarda lo step di scrittura, puoi gestirlo come preferisci: salvarlo in un database, scriverlo in un altro file, qualsiasi cosa tu voglia fare.
Per questo, considereremo il template qui sotto:
| CAMPO | INIZIO | FINE | LUNGHEZZA | FORMATO (COBOL PIC) | TIPO DATI | DESCRIZIONE |
|---|---|---|---|---|---|---|
| COMIC-TITLE | 01 | 30 | 30 | PIC X(30) | ALFANUMERICO | Il titolo del fumetto. Allineato a sinistra, riempito con spazi. |
| ISSUE-NUM | 31 | 35 | 05 | PIC 9(05) | NUMERICO (ZONED) | Il numero di sequenza dell’uscita. Allineato a destra, riempito con zeri. |
| PUBLISHER | 36 | 55 | 20 | PIC X(20) | ALFANUMERICO | Il nome dell’editore. Allineato a sinistra, riempito con spazi. |
| PUB-DATE | 56 | 65 | 10 | PIC X(10) | DATA (ISO) | Data di pubblicazione in formato YYYY-MM-DD. Trattato come testo. |
| CVR-PRICE | 66 | 72 | 07 | PIC 9(07) | NUMERICO (ZONED) | Prezzo di copertina. Allineato a destra, riempito con zeri. Nota: la gestione dei decimali dipende dalla logica di parsing. |
E supponiamo di ricevere il file qui sotto sulla piattaforma distribuita. Nota che quando si tratta di formati numerici (PIC 9), riempiamo il campo con zeri iniziali, e per i campi alfanumerici (PIC X), riempiamo la lunghezza fissa con spazi finali.
Action Comics 00001DC Comics 1938-04-180000.10
Detective Comics 00027DC Comics 1939-03-300000.10
Batman 00001DC Comics 1940-04-240000.10
Superman 00001DC Comics 1939-05-180000.10
Wonder Woman 00001DC Comics 1942-07-220000.10
Flash Comics 00001DC Comics 1940-01-010000.10
Green Lantern 00001DC Comics 1941-07-010000.10
Amazing Fantasy 00015Marvel 1962-08-100000.12
The Incredible Hulk 00001Marvel 1962-05-010000.12
Fantastic Four 00001Marvel 1961-11-010000.10
Journey into Mystery 00083Marvel 1962-08-010000.12
Tales of Suspense 00039Marvel 1963-03-010000.12
The X-Men 00001Marvel 1963-09-010000.12
The Avengers 00001Marvel 1963-09-010000.12
Daredevil 00001Marvel 1964-04-010000.12
Showcase 00004DC Comics 1956-09-010000.10
Justice League of America 00001DC Comics 1960-10-010000.10
The Brave and the Bold 00028DC Comics 1960-02-010000.10
Swamp Thing 00001DC Comics 1972-10-010000.20
Giant-Size X-Men 00001Marvel 1975-05-010000.50
Crisis on Infinite Earths 00001DC Comics 1985-04-010000.75
Watchmen 00001DC Comics 1986-09-010001.50
The Dark Knight Returns 00001DC Comics 1986-02-010002.95
Maus 00001Pantheon 1986-01-010003.50
Sandman 00001Vertigo 1989-01-010001.50
Spawn 00001Image Comics 1992-05-010001.95
Savage Dragon 00001Image Comics 1992-06-010001.95
WildC.A.T.s 00001Image Comics 1992-08-010001.95
Youngblood 00001Image Comics 1992-04-010002.50
Hellboy: Seed of Destruction 00001Dark Horse 1994-03-010002.50
Sin City 00001Dark Horse 1991-04-010002.25
Preacher 00001Vertigo 1995-04-010002.50
The Walking Dead 00001Image Comics 2003-10-010002.99
Invincible 00001Image Comics 2003-01-010002.99
Saga 00001Image Comics 2012-03-140002.99
Paper Girls 00001Image Comics 2015-10-070002.99
Monstress 00001Image Comics 2015-11-040004.99
Descender 00001Image Comics 2015-03-040002.99
East of West 00001Image Comics 2013-03-270003.50
Ms. Marvel 00001Marvel 2014-02-010002.99
Miles Morales: Spider-Man 00001Marvel 2018-12-120003.99
House of X 00001Marvel 2019-07-240005.99
Powers of X 00001Marvel 2019-07-310005.99
Batman: Court of Owls 00001DC Comics 2011-09-210002.99
Doomsday Clock 00001DC Comics 2017-11-220004.99
Immortal Hulk 00001Marvel 2018-06-060004.99
Something is Killing Child 00001BOOM! Studios 2019-09-040003.99
Department of Truth 00001Image Comics 2020-09-300003.99
Nice House on the Lake 00001DC Black Label 2021-06-010003.99
Ultimate Spider-Man 00001Marvel 2024-01-100005.99
Iniziamo.
1. Configurazione iniziale che ogni sviluppatore Java odia
Per velocizzare la creazione della base, ho impostato un progetto utilizzando spring initializr. In pratica, ho creato un progetto Spring Boot con Maven, Java 21 e Spring Boot 4.0.0. Sì, l’ho creato senza alcuna dipendenza, dato che modificherò manualmente il pom.xml. Credo che Spring Boot 4.0 includa già Spring Batch 6 (se aggiunto come dipendenza), ma onestamente, ci sono cose che preferisco sistemare manualmente.
Con il progetto creato, costruiamo il nostro pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>4.0.0</version>
<relativePath/>
</parent>
<groupId>me.doismiu</groupId>
<artifactId>spring-batch-bean-io</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>spring-batch-bean-io</name>
<description>Spring Batch 6 BeanIO Example</description>
<properties>
<java.version>21</java.version>
<spring-batch.version>6.0.0</spring-batch.version>
<spring-framework.version>7.0.0</spring-framework.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.beanio</groupId>
<artifactId>beanio</artifactId>
<version>2.1.0</version>
<exclusions>
<exclusion>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-core</artifactId>
</exclusion>
<exclusion>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-infrastructure</artifactId>
</exclusion>
<exclusion>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jsr310</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
<pluginRepository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</pluginRepository>
</pluginRepositories>
</project>
Come avrai notato, lavoreremo con le seguenti librerie in questo progetto:
Spring Batch 6.0
Spring Boot 4.0.0
Spring Boot Starter JDBC. Dato che dobbiamo configurare il
TransactionManagerper la connessione al database, avremo bisogno di questa libreria.BeanIO 2.1.0. La libreria che esegue la magia di convertire campi posizionali in attributi di oggetti; inoltre, viene fornita con una serie di classi speciali per Spring Batch!
Librerie Jackson per convertire facilmente l’oggetto in una struttura JSON nel nostro Writer.
Ora, creeremo la nostra struttura Main e la connessione al database. Qui vediamo il primo grande cambiamento in Spring Batch 6: la cosiddetta "Infrastruttura batch senza risorse per impostazione predefinita". Chiunque abbia lavorato con Spring Batch sa che era quasi sempre necessario collegare il Batch a un database, poiché questa tecnologia memorizza i metadati per le esecuzioni di Job e Step, che sono di estrema importanza per il controllo dell’esecuzione. Tuttavia, nell’ultima versione, Batch non ha bisogno di essere collegato a nessun database per impostazione predefinita. Come ho detto, poiché questo è importante, lo configureremo comunque. Nel nostro scenario, il batch richiede la struttura qui sotto per funzionare:
In questo progetto, ho utilizzato PostgreSQL via Docker per semplificare le cose, ma dovrebbe funzionare con qualsiasi database, anche NoSQL come MongoDB. Per fare ciò, ho creato il seguente docker compose.
version: '3.8'
services:
postgres:
image: postgres:15-alpine
container_name: comic_postgres
environment:
POSTGRES_USER: user
POSTGRES_PASSWORD: password
POSTGRES_DB: comicbatch
ports:
- "5432:5432"
volumes:
- postgres_data:/var/lib/postgresql/data
volumes:
postgres_data:
Ma come ho detto, qualsiasi database andrà bene. Dopo aver avviato il docker compose, avremo un container chiamato comic_postgres in esecuzione sul nostro Docker locale. Con ciò, possiamo procedere a configurare il file application.properties del nostro progetto.
spring.application.name=spring-batch-bean-io
spring.datasource.url=jdbc:postgresql://localhost:5432/comicbatch
spring.datasource.username=user
spring.datasource.password=password
spring.datasource.driver-class-name=org.postgresql.Driver
logging.level.org.springframework.jdbc.core=DEBUG
logging.level.org.springframework.transaction=DEBUG
spring.batch.jdbc.initialize-schema=never
Qui ho configurato JDBC per non creare tabelle all’inizializzazione. TEORICAMENTE, Batch dovrebbe creare la struttura dei metadati senza problemi, ma ammetto di aver utilizzato estensivamente le versioni 4 e 5 di Spring Batch, e MAI ha creato la struttura correttamente. Questo porta a errori durante l’esecuzione dell’applicazione, molto probabilmente a causa di colonne mancanti o tipi errati. Ancora peggio sarebbe prendere uno script a caso da internet e creare le tabelle direttamente nel database. Invece, abbiamo una soluzione che legge la struttura corretta fornita dalla libreria stessa e la adatta al tipo di database che stiamo utilizzando. Ecco come appare la nostra classe Main, implementando questa logica del database:
package me.doismiu.fixedlength;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.core.io.ClassPathResource;
import org.springframework.jdbc.datasource.init.DataSourceInitializer;
import org.springframework.jdbc.datasource.init.ResourceDatabasePopulator;
import javax.sql.DataSource;
@SpringBootApplication
public class ComicBatchApplication {
public static void main(String[] args) {
System.exit(
SpringApplication.exit(
SpringApplication.run(ComicBatchApplication.class, args)));
}
@Bean
public DataSourceInitializer databaseInitializer(DataSource dataSource) {
ResourceDatabasePopulator populator = new ResourceDatabasePopulator();
populator.addScript(new ClassPathResource("org/springframework/batch/core/schema-postgresql.sql"));
populator.setContinueOnError(true);
DataSourceInitializer initializer = new DataSourceInitializer();
initializer.setDataSource(dataSource);
initializer.setDatabasePopulator(populator);
return initializer;
}
}
Ciò garantisce che alla prima esecuzione del Batch, crei la struttura appropriata prevista dal framework, poiché il file di creazione è fornito da Spring Batch stesso. Nota che ho incluso anche la riga populator.setContinueOnError(true). Ciò significa che ogni volta che ci sarà un errore nella struttura SQL, verrà ignorato, dato che questo script verrà eseguito ad ogni esecuzione del Batch. Ci sono modi più eleganti per gestire questo, o potresti anche rimuovere questo metodo dopo la prima esecuzione se preferisci. Ma per il nostro esempio, funziona bene.
Approfittiamone per finalizzare la configurazione del database creando una classe vuota, ma con annotazioni che specificano la configurazione del TransactionManager:
package me.doismiu.fixedlength.config;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.EnableJdbcJobRepository;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.annotation.Isolation;
@Configuration
@EnableBatchProcessing
@EnableJdbcJobRepository(dataSourceRef = "dataSource", transactionManagerRef = "transactionManager", isolationLevelForCreate = Isolation.READ_COMMITTED, tablePrefix = "BATCH_")
public class JDBCJobRepositoryConfig {
}
2. L’oggetto con annotazioni BeanIO
Per questo progetto, dobbiamo creare un modello chiamato Comic contenente le informazioni del template posizionale che ho mostrato all’inizio del post. Possiamo farlo via XML o via annotazione, è una questione di gusti personali. Nell’esempio di questo progetto, utilizzerò la versione con annotazioni, poiché sento che organizza la struttura di un template posizionale in modo più semplice.
package me.doismiu.fixedlength.model;
import org.beanio.annotation.Field;
import org.beanio.annotation.Record;
import org.beanio.builder.Align;
import java.math.BigDecimal;
import java.time.LocalDate;
@Record
public class Comic {
@Field(at = 0, length = 30, padding = ' ', align = Align.LEFT)
private String title;
@Field(at = 30, length = 5, padding = '0', align = Align.RIGHT)
private int issueNumber;
@Field(at = 35, length = 20, padding = ' ', align = Align.LEFT)
private String publisher;
@Field(at = 55, length = 10, format = "yyyy-MM-dd")
private LocalDate publicationDate;
@Field(at = 65, length = 7, padding = '0', align = Align.RIGHT)
private BigDecimal coverPrice;
// Getters and Setters
}
Per quanto riguarda il modello, alcuni punti meritano di essere evidenziati:
Gli attributi non devono necessariamente essere nell’ordine del template, ma raccomando vivamente di mantenerlo così per facilitare la manutenzione del codice.
Utilizziamo la logica padding + align per riempire con zeri iniziali o spazi finali, come stabilito nel layout del file. Inoltre, diciamo a BeanIO che il campo data previsto ha un formato definito. Ne parleremo più approfonditamente quando scriveremo il Reader dell’applicazione.
E questo è tutto, semplice così. Ora passiamo alla creazione del nostro Reader e Writer.
3. Un Reader che giustifica l’esistenza di questo post, un Writer che fa quello che diavolo vuole
Tipicamente, la logica Batch impone di creare un’applicazione nel seguente ordine: Job -> Step -> Reader/Processor/Writer. Ma poiché ogni pezzo dipende dal successivo, inizieremo dalla fine.
Nel nostro Reader, utilizzeremo il meglio che BeanIO offre per i Batch. Creeremo la nostra logica di lettura del file utilizzando lo standard StreamBuilder della libreria. Utilizzeremo anche la logica Skip di BeanIO per evitare di rileggere le voci del database quando si riprende un servizio che è stato interrotto. Per far funzionare questo, invece di utilizzare il Batch standard FileFlatItemReader, utilizzeremo AbstractItemCountingItemStreamItemReader. Questo ci consente di riprendere qualsiasi processo di lettura che è stato interrotto, combinato con la logica JumpItem che creiamo con BeanIO. In pratica, configureremo lo StreamBuilder nel costruttore della classe e gestiremo correttamente l’apertura e la chiusura degli stream. Questo ci dà il seguente reader:
package me.doismiu.fixedlength.reader;
import me.doismiu.fixedlength.handler.LocalDateTypeHandler;
import me.doismiu.fixedlength.model.Comic;
import org.beanio.BeanReader;
import org.beanio.StreamFactory;
import org.beanio.builder.FixedLengthParserBuilder;
import org.beanio.builder.StreamBuilder;
import org.springframework.batch.infrastructure.item.ItemStreamException;
import org.springframework.batch.infrastructure.item.support.AbstractItemCountingItemStreamItemReader;
import org.springframework.core.io.Resource;
import org.springframework.util.Assert;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
import java.time.LocalDate;
public class ComicItemsReader extends AbstractItemCountingItemStreamItemReader<Comic> {
private final Resource resource;
private final StreamFactory streamFactory;
private BeanReader beanReader;
public ComicItemsReader(Resource resource) {
this.resource = resource;
setName("comicItemsReader");
this.streamFactory = StreamFactory.newInstance();
StreamBuilder builder = new StreamBuilder("comicStream")
.format("fixedlength")
.parser(new FixedLengthParserBuilder())
.addTypeHandler(LocalDate.class, new LocalDateTypeHandler("yyyy-MM-dd"))
.addRecord(Comic.class);
this.streamFactory.define(builder);
}
@Override
protected void jumpToItem(int itemIndex) throws Exception {
if (beanReader != null) {
beanReader.skip(itemIndex);
}
}
@Override
protected void doOpen() throws Exception {
Assert.notNull(resource, "Input resource must be set");
if (!resource.exists()) {
throw new ItemStreamException("Input resource does not exist: " + resource);
}
this.beanReader = streamFactory.createReader(
"comicStream",
new InputStreamReader(resource.getInputStream(), StandardCharsets.UTF_8));
}
@Override
protected Comic doRead() throws Exception {
if (beanReader == null) {
return null;
}
return (Comic) beanReader.read();
}
@Override
protected void doClose() throws Exception {
if (beanReader != null) {
beanReader.close();
beanReader = null;
}
}
}
Nota che quando si implementa questa classe, il compilatore segnalerà un errore sulla seguente riga:
.addTypeHandler(LocalDate.class, new LocalDateTypeHandler("yyyy-MM-dd"))
Questo perché non abbiamo ancora creato il LocalDateTypeHandler. E perché abbiamo bisogno di un gestore specifico per le date? In un’applicazione di esempio, potrei ignorare un attributo LocalDate e gestire tutto come Stringhe e Interi. Ma come ho detto, uno dei principali tipi di file elaborati nei batch riguarda i pagamenti. E i pagamenti hanno date. Vogliamo essere in grado di manipolare questo attributo come una data. Se eseguiamo il reader senza la nostra logica TypeHandler, otterremo il seguente errore:
org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'importComicJob' defined in class path resource [me/doismiu/fixedlength/job/ComicPrinterJob.class]: Unsatisfied dependency expressed through method 'importComicJob' parameter 1: Error creating bean with name 'printStep' defined in class path resource [me/doismiu/fixedlength/step/ComicPrinterStep.class]: Unsatisfied dependency expressed through method 'printStep' parameter 2: Error creating bean with name 'comicItemsReader' defined in class path resource [me/doismiu/fixedlength/step/ComicPrinterStep.class]: Failed to instantiate [me.doismiu.fixedlength.reader.ComicItemsReader]: Factory method 'comicItemsReader' threw exception with message: Invalid field 'publicationDate', in record 'comic', in stream 'comicStream': Type handler not found for type 'java.time.LocalDate'
In breve: BeanIO non fornisce un TypeHandler predefinito per LocalDate con il formato che vogliamo. Ecco perché creeremo una classe per risolvere questo.
package me.doismiu.fixedlength.handler;
import org.beanio.types.ConfigurableTypeHandler;
import org.beanio.types.TypeHandler;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.util.Properties;
public class LocalDateTypeHandler implements ConfigurableTypeHandler {
private final DateTimeFormatter formatter;
public LocalDateTypeHandler(String pattern) {
this.formatter = DateTimeFormatter.ofPattern(pattern);
}
@Override
public TypeHandler newInstance(Properties properties) throws IllegalArgumentException {
String format = properties.getProperty("format");
if (format == null || format.isEmpty()) {
return this;
}
return new LocalDateTypeHandler(format);
}
@Override
public Object parse(String text) {
if (text == null || text.trim().isEmpty()) {
return null;
}
return LocalDate.parse(text, formatter);
}
@Override
public String format(Object value) {
if (value == null) {
return null;
}
return ((LocalDate) value).format(formatter);
}
@Override
public Class<?> getType() {
return LocalDate.class;
}
}
In pratica, stiamo registrando il nostro tipo di formato personalizzato, semplice così. Ora abbiamo finalmente creato il nostro LocalDateTypeHandler e collegato al nostro Reader. È così facile.
Per il nostro Writer, come specificato, l’ambito di questo progetto è solo mostrare l’output del file in console come JSON per dimostrare che stiamo utilizzando Oggetti reali. Qui, semplicemente implementare ItemWriter è sufficiente. Ma puoi fare quello che vuoi con i dati; dipende da te. Non mi soffermerò ulteriormente sul Writer.
package me.doismiu.fixedlength.writer;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.SerializationFeature;
import com.fasterxml.jackson.datatype.jsr310.JavaTimeModule;
import me.doismiu.fixedlength.model.Comic;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.infrastructure.item.Chunk;
import org.springframework.batch.infrastructure.item.ItemWriter;
import org.springframework.stereotype.Component;
import java.util.List;
@Component
public class ComicPrinterWriter implements ItemWriter<Comic> {
private static final Logger LOGGER = LoggerFactory.getLogger(ComicPrinterWriter.class);
private final ObjectMapper objectMapper;
public ComicPrinterWriter() {
this.objectMapper = new ObjectMapper();
this.objectMapper.registerModule(new JavaTimeModule());
this.objectMapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
this.objectMapper.enable(SerializationFeature.INDENT_OUTPUT);
}
@Override
public void write(Chunk<? extends Comic> chunk) throws Exception {
LOGGER.info("--- Writing Batch of {} items as JSON ---", chunk.size());
List<? extends Comic> items = chunk.getItems();
String jsonOutput = objectMapper.writeValueAsString(items);
System.out.println(jsonOutput);
}
}
4. Il Job e lo Step mancanti per finalizzare il progetto
Con il Reader e il Writer creati, generiamo lo Step che orchestrerà entrambi. Niente di complesso qui, solo uno Step standard con un po’ di gestione degli errori e dove specifichiamo la Resource per il nostro file TXT. Se stai utilizzando questo esempio per la Produzione, la gestione dovrebbe essere più specifica, così come la logica per restituire correttamente il codice di uscita dell’applicazione. Ma per il nostro esempio, il codice qui sotto funziona:
package me.doismiu.fixedlength.step;
import me.doismiu.fixedlength.model.Comic;
import me.doismiu.fixedlength.reader.ComicItemsReader;
import me.doismiu.fixedlength.writer.ComicPrinterWriter;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.Step;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.FileSystemResource;
import org.springframework.transaction.PlatformTransactionManager;
@Configuration
public class ComicPrinterStep {
@Value("${input.file.path:data/comics.txt}")
private String inputFilePath;
@Bean
public ComicItemsReader comicItemsReader() {
return new ComicItemsReader(new FileSystemResource(inputFilePath));
}
@Bean
public Step printStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager,
ComicItemsReader reader,
ComicPrinterWriter writer) {
return new StepBuilder("comicPrinterStep", jobRepository)
.<Comic, Comic>chunk(10)
.transactionManager(transactionManager)
.reader(reader)
.writer(writer)
.faultTolerant()
.skipLimit(1)
.skip(IllegalArgumentException.class)
.build();
}
}
E con ciò, abbiamo creato il nostro Job.
package me.doismiu.fixedlength.job;
import org.springframework.batch.core.configuration.annotation.EnableJdbcJobRepository;
import org.springframework.batch.core.job.Job;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.job.parameters.RunIdIncrementer;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.Step;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.annotation.Isolation;
@Configuration
public class ComicPrinterJob {
@Bean
public Job importComicJob(JobRepository jobRepository, Step printStep) {
return new JobBuilder("importComicJob", jobRepository)
.incrementer(new RunIdIncrementer())
.start(printStep)
.build();
}
}
E con ciò, abbiamo creato il nostro Job.Con ciò, abbiamo l’intera struttura impostata.
5. Testare ciò che deve essere testato
Ora siamo pronti per eseguire la nostra applicazione finale.
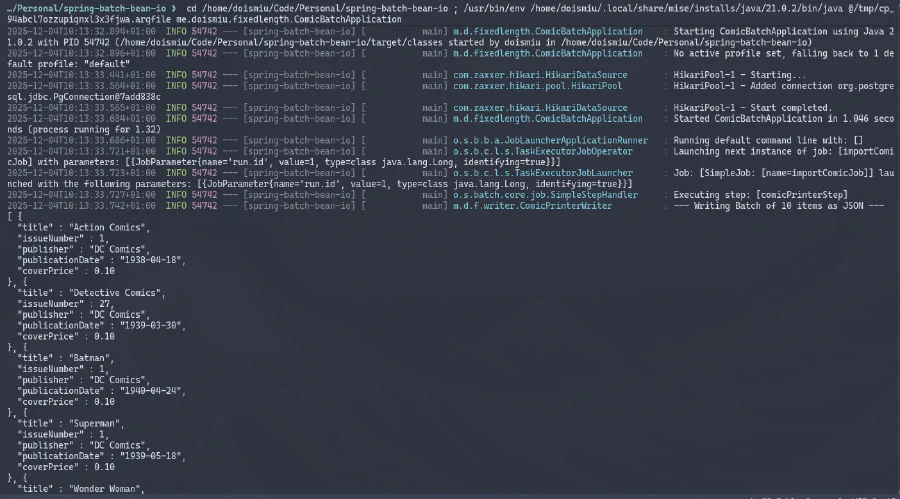
Possiamo osservare il JSON generato nella console e la connessione al database stabilita con successo. E poiché abbiamo creato una struttura di metadati per controllare l’esecuzione, possiamo andare direttamente al database per verificare i dettagli dell’esecuzione:
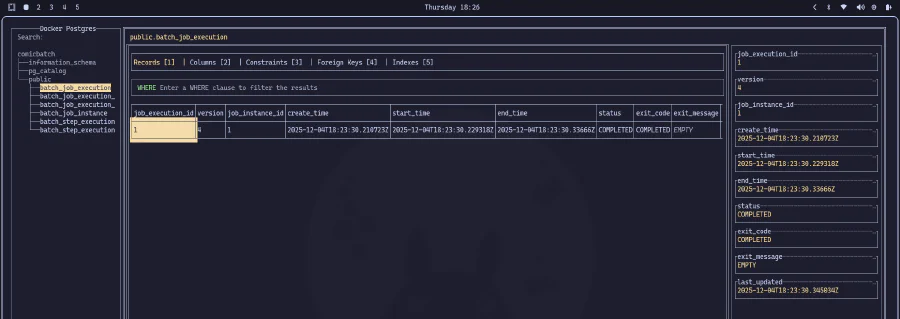
GRANDE SUCCESSO!
6. Conclusione
Con questo, ora abbiamo la logica di base per leggere file posizionali a larghezza fissa. Non è nulla di complesso, ma poiché questo blog mira a essere un backup delle mie conoscenze, almeno lascio una traccia qui per non dimenticarlo di nuovo.

Alla prossima!
