





Fichiers à Longueur Fixe Avec Spring Batch 6.0 : La « Joie » des Données Legacy
Si vous êtes un développeur qui a déjà géré du traitement de paie ou de la réconciliation bancaire/financière dans une entreprise utilisant Spring, vous avez probablement travaillé avec Spring Batch. J’avoue que je n’en suis pas un grand fan ; il a cette verbosité et cette lourdeur caractéristique de l’écosystème Java, donnant l’impression que même le job le plus simple nécessite bien plus de structure que nécessaire. Mais à quoi bon se plaindre ? La technologie que votre entreprise utilise est ce qui assure votre survie (logement, nourriture, vêtements). Donc, râler n’est pas le sujet du jour.
Le périmètre de cet article est extrêmement simple : étant donné un fichier positionnel généré via un mainframe en utilisant le modèle ci-dessous, nous allons créer une application Spring Batch (en utilisant la version 6.0, la plus récente à ce jour) pour lire facilement le fichier, créer un objet, et afficher le contenu dans la console au format JSON. La partie clé ici est la lecture du fichier et sa transformation en un objet Java standard. Quant à l’étape d’écriture, vous pouvez la gérer comme vous voulez : l’enregistrer dans une base de données, l’écrire dans un autre fichier, peu importe ce que vous voulez en faire.
Pour cela, nous considérerons le modèle ci-dessous :
| CHAMP | DÉBUT | FIN | LONGUEUR | FORMAT (COBOL PIC) | TYPE DE DONNÉES | DESCRIPTION |
|---|---|---|---|---|---|---|
| COMIC-TITLE | 01 | 30 | 30 | PIC X(30) | ALPHANUMÉRIQUE | Le titre de la bande dessinée. Aligné à gauche, complété par des espaces. |
| ISSUE-NUM | 31 | 35 | 05 | PIC 9(05) | NUMÉRIQUE (ZONÉ) | Le numéro de séquence de l’édition. Aligné à droite, complété par des zéros. |
| PUBLISHER | 36 | 55 | 20 | PIC X(20) | ALPHANUMÉRIQUE | Le nom de l’éditeur. Aligné à gauche, complété par des espaces. |
| PUB-DATE | 56 | 65 | 10 | PIC X(10) | DATE (ISO) | Date de publication au format YYYY-MM-DD. Traité comme texte. |
| CVR-PRICE | 66 | 72 | 07 | PIC 9(07) | NUMÉRIQUE (ZONÉ) | Prix de couverture. Aligné à droite, complété par des zéros. Note : La gestion des décimales dépend de la logique d’analyse. |
Et supposons que nous recevions le fichier ci-dessous sur la plateforme distribuée. Notez que lorsque nous traitons des formats numériques (PIC 9), nous remplissons le champ avec des zéros non significatifs, et pour les champs alphanumériques (PIC X), nous complétons la longueur fixe avec des espaces de fin.
Action Comics 00001DC Comics 1938-04-180000.10
Detective Comics 00027DC Comics 1939-03-300000.10
Batman 00001DC Comics 1940-04-240000.10
Superman 00001DC Comics 1939-05-180000.10
Wonder Woman 00001DC Comics 1942-07-220000.10
Flash Comics 00001DC Comics 1940-01-010000.10
Green Lantern 00001DC Comics 1941-07-010000.10
Amazing Fantasy 00015Marvel 1962-08-100000.12
The Incredible Hulk 00001Marvel 1962-05-010000.12
Fantastic Four 00001Marvel 1961-11-010000.10
Journey into Mystery 00083Marvel 1962-08-010000.12
Tales of Suspense 00039Marvel 1963-03-010000.12
The X-Men 00001Marvel 1963-09-010000.12
The Avengers 00001Marvel 1963-09-010000.12
Daredevil 00001Marvel 1964-04-010000.12
Showcase 00004DC Comics 1956-09-010000.10
Justice League of America 00001DC Comics 1960-10-010000.10
The Brave and the Bold 00028DC Comics 1960-02-010000.10
Swamp Thing 00001DC Comics 1972-10-010000.20
Giant-Size X-Men 00001Marvel 1975-05-010000.50
Crisis on Infinite Earths 00001DC Comics 1985-04-010000.75
Watchmen 00001DC Comics 1986-09-010001.50
The Dark Knight Returns 00001DC Comics 1986-02-010002.95
Maus 00001Pantheon 1986-01-010003.50
Sandman 00001Vertigo 1989-01-010001.50
Spawn 00001Image Comics 1992-05-010001.95
Savage Dragon 00001Image Comics 1992-06-010001.95
WildC.A.T.s 00001Image Comics 1992-08-010001.95
Youngblood 00001Image Comics 1992-04-010002.50
Hellboy: Seed of Destruction 00001Dark Horse 1994-03-010002.50
Sin City 00001Dark Horse 1991-04-010002.25
Preacher 00001Vertigo 1995-04-010002.50
The Walking Dead 00001Image Comics 2003-10-010002.99
Invincible 00001Image Comics 2003-01-010002.99
Saga 00001Image Comics 2012-03-140002.99
Paper Girls 00001Image Comics 2015-10-070002.99
Monstress 00001Image Comics 2015-11-040004.99
Descender 00001Image Comics 2015-03-040002.99
East of West 00001Image Comics 2013-03-270003.50
Ms. Marvel 00001Marvel 2014-02-010002.99
Miles Morales: Spider-Man 00001Marvel 2018-12-120003.99
House of X 00001Marvel 2019-07-240005.99
Powers of X 00001Marvel 2019-07-310005.99
Batman: Court of Owls 00001DC Comics 2011-09-210002.99
Doomsday Clock 00001DC Comics 2017-11-220004.99
Immortal Hulk 00001Marvel 2018-06-060004.99
Something is Killing Child 00001BOOM! Studios 2019-09-040003.99
Department of Truth 00001Image Comics 2020-09-300003.99
Nice House on the Lake 00001DC Black Label 2021-06-010003.99
Ultimate Spider-Man 00001Marvel 2024-01-100005.99
Commençons.
1. Configuration initiale que tout dev Java déteste
Pour accélérer la création de la base, j’ai configuré un projet en utilisant spring initializr. En gros, j’ai créé un projet Spring Boot avec Maven, Java 21, et Spring Boot 4.0.0. Oui, je l’ai créé sans aucune dépendance, puisque je vais éditer manuellement le pom.xml. Je pense que Spring Boot 4.0 embarque déjà Spring Batch 6 (si ajouté comme dépendance), mais honnêtement, il y a des choses que je préfère ajuster manuellement.
Avec le projet créé, construisons notre pom.xml :
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>4.0.0</version>
<relativePath/>
</parent>
<groupId>me.doismiu</groupId>
<artifactId>spring-batch-bean-io</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>spring-batch-bean-io</name>
<description>Spring Batch 6 BeanIO Example</description>
<properties>
<java.version>21</java.version>
<spring-batch.version>6.0.0</spring-batch.version>
<spring-framework.version>7.0.0</spring-framework.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.beanio</groupId>
<artifactId>beanio</artifactId>
<version>2.1.0</version>
<exclusions>
<exclusion>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-core</artifactId>
</exclusion>
<exclusion>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-infrastructure</artifactId>
</exclusion>
<exclusion>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jsr310</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
<pluginRepository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</pluginRepository>
</pluginRepositories>
</project>
Comme vous l’avez peut-être remarqué, nous allons travailler avec les libs suivantes dans ce projet :
Spring Batch 6.0
Spring Boot 4.0.0
Spring Boot Starter JDBC. Puisque nous devons configurer le
TransactionManagerpour la connexion à la base de données, nous aurons besoin de cette lib.BeanIO 2.1.0. La lib qui fait la magie de convertir les champs positionnels en attributs d’objet ; en plus, elle vient avec une série de classes spéciales pour Spring Batch !
Les libs Jackson pour convertir facilement l’objet en une structure JSON dans notre Writer.
Maintenant, nous allons créer notre structure Main et la connexion à la base de données. Ici, nous voyons le premier changement majeur dans Spring Batch 6 : le soi-disant "Infrastructure batch sans ressource par défaut". Quiconque a travaillé avec Spring Batch sait qu’il était presque toujours nécessaire de lier le Batch à une base de données, car cette technologie stocke les métadonnées des exécutions de Job et Step, qui sont extrêmement importantes pour le contrôle d’exécution. Cependant, dans la dernière version, Batch n’a pas besoin d’être lié à une base de données par défaut. Comme je l’ai mentionné, puisque c’est important, nous allons le configurer quand même. Dans notre scénario, le batch nécessite la structure ci-dessous pour s’exécuter :
Dans ce projet, j’ai utilisé PostgreSQL via Docker pour simplifier les choses, mais cela devrait fonctionner avec n’importe quelle base de données, même NoSQL comme MongoDB. Pour cela, j’ai créé le docker compose suivant.
version: '3.8'
services:
postgres:
image: postgres:15-alpine
container_name: comic_postgres
environment:
POSTGRES_USER: user
POSTGRES_PASSWORD: password
POSTGRES_DB: comicbatch
ports:
- "5432:5432"
volumes:
- postgres_data:/var/lib/postgresql/data
volumes:
postgres_data:
Mais comme je l’ai dit, n’importe quelle base de données fera l’affaire. Après avoir lancé le docker compose, nous aurons un conteneur nommé comic_postgres qui tourne sur notre Docker local. Avec cela, nous pouvons procéder à la configuration de notre fichier application.properties du projet.
spring.application.name=spring-batch-bean-io
spring.datasource.url=jdbc:postgresql://localhost:5432/comicbatch
spring.datasource.username=user
spring.datasource.password=password
spring.datasource.driver-class-name=org.postgresql.Driver
logging.level.org.springframework.jdbc.core=DEBUG
logging.level.org.springframework.transaction=DEBUG
spring.batch.jdbc.initialize-schema=never
Ici, j’ai configuré JDBC pour ne pas créer de tables lors de l’initialisation. THÉORIQUEMENT, Batch devrait créer la structure de métadonnées sans aucun problème, mais j’avoue que j’ai beaucoup utilisé les versions 4 et 5 de Spring Batch, et cela N’A JAMAIS créé la structure correctement. Cela conduit à des erreurs d’exécution de l’application, très probablement dues à des colonnes manquantes ou à un typage incorrect. Pire encore serait de prendre un script aléatoire sur Internet et de créer les tables directement dans la base de données. Au lieu de cela, nous avons une solution qui lit la structure correcte fournie par la librairie elle-même et l’adapte au type de base de données que nous utilisons. Voici à quoi ressemble notre classe Main, implémentant cette logique de base de données :
package me.doismiu.fixedlength;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.core.io.ClassPathResource;
import org.springframework.jdbc.datasource.init.DataSourceInitializer;
import org.springframework.jdbc.datasource.init.ResourceDatabasePopulator;
import javax.sql.DataSource;
@SpringBootApplication
public class ComicBatchApplication {
public static void main(String[] args) {
System.exit(
SpringApplication.exit(
SpringApplication.run(ComicBatchApplication.class, args)));
}
@Bean
public DataSourceInitializer databaseInitializer(DataSource dataSource) {
ResourceDatabasePopulator populator = new ResourceDatabasePopulator();
populator.addScript(new ClassPathResource("org/springframework/batch/core/schema-postgresql.sql"));
populator.setContinueOnError(true);
DataSourceInitializer initializer = new DataSourceInitializer();
initializer.setDataSource(dataSource);
initializer.setDatabasePopulator(populator);
return initializer;
}
}
Cela garantit qu’à la première exécution du Batch, il crée la structure appropriée attendue par le framework, puisque le fichier de création est fourni par Spring Batch lui-même. Notez que j’ai également inclus la ligne populator.setContinueOnError(true). Cela signifie que chaque fois qu’il y a une erreur de structure SQL, elle sera ignorée, étant donné que ce script s’exécutera à chaque exécution du Batch. Il existe des façons plus élégantes de gérer cela, ou vous pourriez même supprimer cette méthode après la première exécution si vous préférez. Mais pour notre exemple, cela fonctionne très bien.
Profitons-en pour finaliser la configuration de la base de données en créant une classe vide, mais avec des annotations spécifiant la configuration du TransactionManager :
package me.doismiu.fixedlength.config;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.EnableJdbcJobRepository;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.annotation.Isolation;
@Configuration
@EnableBatchProcessing
@EnableJdbcJobRepository(dataSourceRef = "dataSource", transactionManagerRef = "transactionManager", isolationLevelForCreate = Isolation.READ_COMMITTED, tablePrefix = "BATCH_")
public class JDBCJobRepositoryConfig {
}
2. L’objet avec les annotations BeanIO
Pour ce projet, nous devons créer un modèle appelé Comic contenant les informations du modèle positionnel que j’ai montré au début de l’article. Nous pouvons le faire via XML ou via annotation, c’est une question de goût personnel. Dans l’exemple de ce projet, j’utiliserai la version par annotation, car je trouve qu’elle organise la structure d’un modèle positionnel plus simplement.
package me.doismiu.fixedlength.model;
import org.beanio.annotation.Field;
import org.beanio.annotation.Record;
import org.beanio.builder.Align;
import java.math.BigDecimal;
import java.time.LocalDate;
@Record
public class Comic {
@Field(at = 0, length = 30, padding = ' ', align = Align.LEFT)
private String title;
@Field(at = 30, length = 5, padding = '0', align = Align.RIGHT)
private int issueNumber;
@Field(at = 35, length = 20, padding = ' ', align = Align.LEFT)
private String publisher;
@Field(at = 55, length = 10, format = "yyyy-MM-dd")
private LocalDate publicationDate;
@Field(at = 65, length = 7, padding = '0', align = Align.RIGHT)
private BigDecimal coverPrice;
// Getters and Setters
}
Concernant le modèle, quelques points méritent d’être soulignés :
Les attributs ne doivent pas nécessairement être dans l’ordre du modèle, mais je recommande fortement de les garder ainsi pour faciliter la maintenance du code.
Nous utilisons la logique padding + align pour remplir avec des zéros non significatifs ou des espaces de fin, comme stipulé dans la mise en page du fichier. De plus, nous indiquons à BeanIO que le champ date attendu a un format défini. Nous en reparlerons lors de l’écriture du Reader de l’application.
Et c’est tout, aussi simple que cela. Passons maintenant à la création de notre Reader et Writer.
3. Un Reader qui justifie l’existence de cet article, un Writer qui fait ce qu’il veut
Typiquement, la logique Batch dicte de créer une application dans l’ordre suivant : Job -> Step -> Reader/Processor/Writer. Mais puisque chaque pièce dépend de la suivante, nous allons commencer par la fin.
Dans notre Reader, nous utiliserons le meilleur que BeanIO offre pour les Batchs. Nous créerons notre logique de lecture de fichier en utilisant le StreamBuilder standard de la librairie. Nous utiliserons également la logique Skip propre à BeanIO pour éviter de relire les entrées de la base de données lors de la reprise d’un service qui a été interrompu. Pour que cela fonctionne, au lieu d’utiliser le FileFlatItemReader standard de Batch, nous utiliserons AbstractItemCountingItemStreamItemReader. Cela nous permet de reprendre tout processus de lecture qui a été interrompu, combiné à la logique JumpItem que nous créons avec BeanIO. En gros, nous configurerons le StreamBuilder dans le constructeur de la classe et gérerons correctement l’ouverture et la fermeture des flux. Cela nous donne le reader suivant :
package me.doismiu.fixedlength.reader;
import me.doismiu.fixedlength.handler.LocalDateTypeHandler;
import me.doismiu.fixedlength.model.Comic;
import org.beanio.BeanReader;
import org.beanio.StreamFactory;
import org.beanio.builder.FixedLengthParserBuilder;
import org.beanio.builder.StreamBuilder;
import org.springframework.batch.infrastructure.item.ItemStreamException;
import org.springframework.batch.infrastructure.item.support.AbstractItemCountingItemStreamItemReader;
import org.springframework.core.io.Resource;
import org.springframework.util.Assert;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
import java.time.LocalDate;
public class ComicItemsReader extends AbstractItemCountingItemStreamItemReader<Comic> {
private final Resource resource;
private final StreamFactory streamFactory;
private BeanReader beanReader;
public ComicItemsReader(Resource resource) {
this.resource = resource;
setName("comicItemsReader");
this.streamFactory = StreamFactory.newInstance();
StreamBuilder builder = new StreamBuilder("comicStream")
.format("fixedlength")
.parser(new FixedLengthParserBuilder())
.addTypeHandler(LocalDate.class, new LocalDateTypeHandler("yyyy-MM-dd"))
.addRecord(Comic.class);
this.streamFactory.define(builder);
}
@Override
protected void jumpToItem(int itemIndex) throws Exception {
if (beanReader != null) {
beanReader.skip(itemIndex);
}
}
@Override
protected void doOpen() throws Exception {
Assert.notNull(resource, "Input resource must be set");
if (!resource.exists()) {
throw new ItemStreamException("Input resource does not exist: " + resource);
}
this.beanReader = streamFactory.createReader(
"comicStream",
new InputStreamReader(resource.getInputStream(), StandardCharsets.UTF_8));
}
@Override
protected Comic doRead() throws Exception {
if (beanReader == null) {
return null;
}
return (Comic) beanReader.read();
}
@Override
protected void doClose() throws Exception {
if (beanReader != null) {
beanReader.close();
beanReader = null;
}
}
}
Notez qu’en implémentant cette classe, le compilateur signalera une erreur sur la ligne suivante :
.addTypeHandler(LocalDate.class, new LocalDateTypeHandler("yyyy-MM-dd"))
C’est parce que nous n’avons pas encore créé le LocalDateTypeHandler. Et pourquoi avons-nous besoin d’un handler spécifique pour les dates ? Dans une application exemple, je pourrais ignorer un attribut LocalDate et tout gérer comme des Strings et des Ints. Mais comme je l’ai dit, l’un des principaux types de fichiers traités dans les batchs concerne les paiements. Et les paiements ont des dates. Nous voulons pouvoir manipuler cet attribut en tant que date. Si nous exécutons le reader sans notre logique TypeHandler, nous obtiendrons l’erreur suivante :
org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'importComicJob' defined in class path resource [me/doismiu/fixedlength/job/ComicPrinterJob.class]: Unsatisfied dependency expressed through method 'importComicJob' parameter 1: Error creating bean with name 'printStep' defined in class path resource [me/doismiu/fixedlength/step/ComicPrinterStep.class]: Unsatisfied dependency expressed through method 'printStep' parameter 2: Error creating bean with name 'comicItemsReader' defined in class path resource [me/doismiu/fixedlength/step/ComicPrinterStep.class]: Failed to instantiate [me.doismiu.fixedlength.reader.ComicItemsReader]: Factory method 'comicItemsReader' threw exception with message: Invalid field 'publicationDate', in record 'comic', in stream 'comicStream': Type handler not found for type 'java.time.LocalDate'
En bref : BeanIO ne fournit pas de TypeHandler par défaut pour LocalDate avec le format que nous voulons. C’est pourquoi nous allons créer une classe pour résoudre cela.
package me.doismiu.fixedlength.handler;
import org.beanio.types.ConfigurableTypeHandler;
import org.beanio.types.TypeHandler;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.util.Properties;
public class LocalDateTypeHandler implements ConfigurableTypeHandler {
private final DateTimeFormatter formatter;
public LocalDateTypeHandler(String pattern) {
this.formatter = DateTimeFormatter.ofPattern(pattern);
}
@Override
public TypeHandler newInstance(Properties properties) throws IllegalArgumentException {
String format = properties.getProperty("format");
if (format == null || format.isEmpty()) {
return this;
}
return new LocalDateTypeHandler(format);
}
@Override
public Object parse(String text) {
if (text == null || text.trim().isEmpty()) {
return null;
}
return LocalDate.parse(text, formatter);
}
@Override
public String format(Object value) {
if (value == null) {
return null;
}
return ((LocalDate) value).format(formatter);
}
@Override
public Class<?> getType() {
return LocalDate.class;
}
}
En gros, nous enregistrons notre type de format personnalisé, aussi simple que cela. Maintenant, nous avons enfin notre LocalDateTypeHandler créé et lié à notre Reader. C’est aussi facile que cela.
Pour notre Writer, comme spécifié, le périmètre de ce projet est juste de montrer la sortie du fichier dans la console en JSON pour prouver que nous utilisons de vrais Objets. Ici, simplement implémenter ItemWriter suffit. Mais vous pouvez faire ce que vous voulez avec les données ; c’est à vous. Je ne m’attarderai pas plus longtemps sur le Writer.
package me.doismiu.fixedlength.writer;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.SerializationFeature;
import com.fasterxml.jackson.datatype.jsr310.JavaTimeModule;
import me.doismiu.fixedlength.model.Comic;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.infrastructure.item.Chunk;
import org.springframework.batch.infrastructure.item.ItemWriter;
import org.springframework.stereotype.Component;
import java.util.List;
@Component
public class ComicPrinterWriter implements ItemWriter<Comic> {
private static final Logger LOGGER = LoggerFactory.getLogger(ComicPrinterWriter.class);
private final ObjectMapper objectMapper;
public ComicPrinterWriter() {
this.objectMapper = new ObjectMapper();
this.objectMapper.registerModule(new JavaTimeModule());
this.objectMapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
this.objectMapper.enable(SerializationFeature.INDENT_OUTPUT);
}
@Override
public void write(Chunk<? extends Comic> chunk) throws Exception {
LOGGER.info("--- Writing Batch of {} items as JSON ---", chunk.size());
List<? extends Comic> items = chunk.getItems();
String jsonOutput = objectMapper.writeValueAsString(items);
System.out.println(jsonOutput);
}
}
4. Le Job et le Step manquants pour finaliser le projet
Avec le Reader et le Writer créés, nous générons le Step qui orchestrera les deux. Rien de complexe ici, juste un Step standard avec un peu de gestion des échecs et où nous spécifions la Resource pour notre fichier TXT. Si vous utilisez cet exemple pour la Production, la gestion devrait être plus spécifique, ainsi que la logique pour retourner correctement le code de sortie de l’application. Mais pour notre exemple, le code ci-dessous fonctionne :
package me.doismiu.fixedlength.step;
import me.doismiu.fixedlength.model.Comic;
import me.doismiu.fixedlength.reader.ComicItemsReader;
import me.doismiu.fixedlength.writer.ComicPrinterWriter;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.Step;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.FileSystemResource;
import org.springframework.transaction.PlatformTransactionManager;
@Configuration
public class ComicPrinterStep {
@Value("${input.file.path:data/comics.txt}")
private String inputFilePath;
@Bean
public ComicItemsReader comicItemsReader() {
return new ComicItemsReader(new FileSystemResource(inputFilePath));
}
@Bean
public Step printStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager,
ComicItemsReader reader,
ComicPrinterWriter writer) {
return new StepBuilder("comicPrinterStep", jobRepository)
.<Comic, Comic>chunk(10)
.transactionManager(transactionManager)
.reader(reader)
.writer(writer)
.faultTolerant()
.skipLimit(1)
.skip(IllegalArgumentException.class)
.build();
}
}
Et avec cela, nous avons créé notre Job.
package me.doismiu.fixedlength.job;
import org.springframework.batch.core.configuration.annotation.EnableJdbcJobRepository;
import org.springframework.batch.core.job.Job;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.job.parameters.RunIdIncrementer;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.Step;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.annotation.Isolation;
@Configuration
public class ComicPrinterJob {
@Bean
public Job importComicJob(JobRepository jobRepository, Step printStep) {
return new JobBuilder("importComicJob", jobRepository)
.incrementer(new RunIdIncrementer())
.start(printStep)
.build();
}
}
Et avec cela, nous avons créé notre Job.Avec cela, nous avons toute la structure mise en place.
5. Tester ce qui doit être testé
Maintenant, nous sommes prêts à exécuter notre application finale.
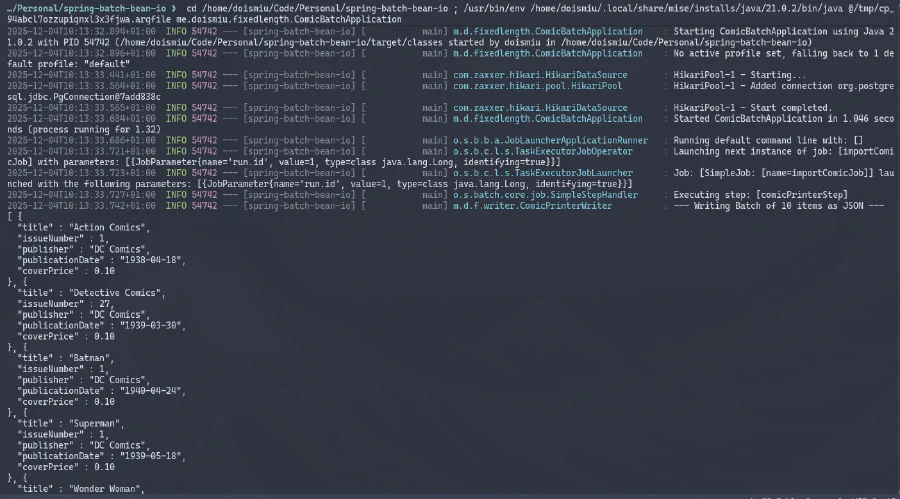
Nous pouvons observer le JSON généré dans la console et la connexion à la base de données établie avec succès. Et puisque nous avons créé une structure de métadonnées pour contrôler l’exécution, nous pouvons aller directement dans la base de données pour vérifier les détails d’exécution :
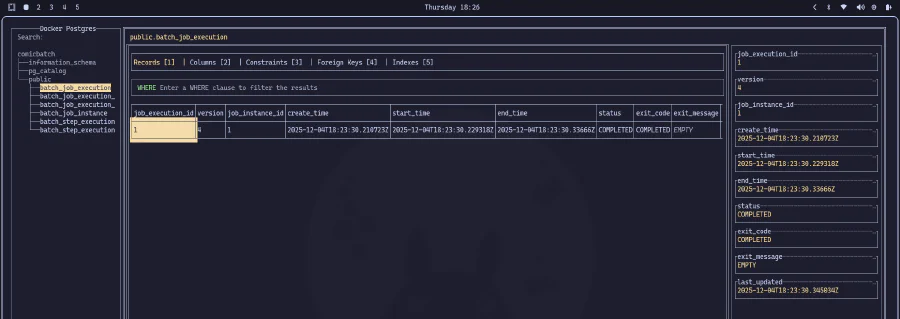
SUCCÈS MONUMENTAL !
6. Conclusion
Avec cela, nous avons maintenant la logique de base pour lire les fichiers positionnels à largeur fixe. Ce n’est rien de complexe, mais puisque ce blog vise à être une sauvegarde de mes connaissances, au moins je laisse une trace ici pour ne pas l’oublier à nouveau.

À la prochaine !
