





Archivos de Longitud Fija con Spring Batch 6.0: La “Alegría” de los Datos Legacy
Si eres un desarrollador que ha manejado procesamiento de nóminas o conciliación bancaria/financiera en una empresa que usa Spring, es probable que hayas trabajado con Spring Batch. Confieso que no soy un gran fan; tiene esa verbosidad y sobrecarga característica del ecosistema Java, haciendo que incluso el trabajo más simple requiera mucha más estructura de la necesaria. Pero ¿de qué sirve quejarse? La tecnología que usa tu empresa es lo que asegura tu supervivencia (vivienda, comida, ropa). Así que, quejarse no es el tema de hoy.
El alcance de esta publicación es extremadamente simple: dado un archivo posicional generado vía un mainframe usando la plantilla de abajo, crearemos una aplicación Spring Batch (usando la versión 6.0, la más reciente al día de hoy) para leer fácilmente el archivo, crear un objeto y mostrar el contenido en la consola en formato JSON. La parte clave aquí es leer el archivo y transformarlo en un objeto Java estándar. En cuanto al paso de escritura, puedes manejarlo como quieras: guardarlo en una base de datos, escribir a otro archivo, lo que diablos quieras hacer.
Para esto, consideraremos la plantilla de abajo:
| CAMPO | INICIO | FIN | LONGITUD | FORMATO (COBOL PIC) | TIPO DE DATO | DESCRIPCIÓN |
|---|---|---|---|---|---|---|
| COMIC-TITLE | 01 | 30 | 30 | PIC X(30) | ALFANUMÉRICO | El título del cómic. Alineado a la izquierda, relleno con espacios. |
| ISSUE-NUM | 31 | 35 | 05 | PIC 9(05) | NUMÉRICO (ZONA) | El número de secuencia de la edición. Alineado a la derecha, relleno con ceros. |
| PUBLISHER | 36 | 55 | 20 | PIC X(20) | ALFANUMÉRICO | El nombre de la editorial. Alineado a la izquierda, relleno con espacios. |
| PUB-DATE | 56 | 65 | 10 | PIC X(10) | FECHA (ISO) | Fecha de publicación en formato YYYY-MM-DD. Tratado como texto. |
| CVR-PRICE | 66 | 72 | 07 | PIC 9(07) | NUMÉRICO (ZONA) | Precio de portada. Alineado a la derecha, relleno con ceros. Nota: El manejo decimal depende de la lógica de análisis. |
Y asumamos que estamos recibiendo el archivo de abajo en la plataforma distribuida. Nota que al manejar formatos numéricos (PIC 9), llenamos el campo con ceros a la izquierda, y para campos alfanuméricos (PIC X), rellenamos la longitud fija con espacios a la derecha.
Action Comics 00001DC Comics 1938-04-180000.10
Detective Comics 00027DC Comics 1939-03-300000.10
Batman 00001DC Comics 1940-04-240000.10
Superman 00001DC Comics 1939-05-180000.10
Wonder Woman 00001DC Comics 1942-07-220000.10
Flash Comics 00001DC Comics 1940-01-010000.10
Green Lantern 00001DC Comics 1941-07-010000.10
Amazing Fantasy 00015Marvel 1962-08-100000.12
The Incredible Hulk 00001Marvel 1962-05-010000.12
Fantastic Four 00001Marvel 1961-11-010000.10
Journey into Mystery 00083Marvel 1962-08-010000.12
Tales of Suspense 00039Marvel 1963-03-010000.12
The X-Men 00001Marvel 1963-09-010000.12
The Avengers 00001Marvel 1963-09-010000.12
Daredevil 00001Marvel 1964-04-010000.12
Showcase 00004DC Comics 1956-09-010000.10
Justice League of America 00001DC Comics 1960-10-010000.10
The Brave and the Bold 00028DC Comics 1960-02-010000.10
Swamp Thing 00001DC Comics 1972-10-010000.20
Giant-Size X-Men 00001Marvel 1975-05-010000.50
Crisis on Infinite Earths 00001DC Comics 1985-04-010000.75
Watchmen 00001DC Comics 1986-09-010001.50
The Dark Knight Returns 00001DC Comics 1986-02-010002.95
Maus 00001Pantheon 1986-01-010003.50
Sandman 00001Vertigo 1989-01-010001.50
Spawn 00001Image Comics 1992-05-010001.95
Savage Dragon 00001Image Comics 1992-06-010001.95
WildC.A.T.s 00001Image Comics 1992-08-010001.95
Youngblood 00001Image Comics 1992-04-010002.50
Hellboy: Seed of Destruction 00001Dark Horse 1994-03-010002.50
Sin City 00001Dark Horse 1991-04-010002.25
Preacher 00001Vertigo 1995-04-010002.50
The Walking Dead 00001Image Comics 2003-10-010002.99
Invincible 00001Image Comics 2003-01-010002.99
Saga 00001Image Comics 2012-03-140002.99
Paper Girls 00001Image Comics 2015-10-070002.99
Monstress 00001Image Comics 2015-11-040004.99
Descender 00001Image Comics 2015-03-040002.99
East of West 00001Image Comics 2013-03-270003.50
Ms. Marvel 00001Marvel 2014-02-010002.99
Miles Morales: Spider-Man 00001Marvel 2018-12-120003.99
House of X 00001Marvel 2019-07-240005.99
Powers of X 00001Marvel 2019-07-310005.99
Batman: Court of Owls 00001DC Comics 2011-09-210002.99
Doomsday Clock 00001DC Comics 2017-11-220004.99
Immortal Hulk 00001Marvel 2018-06-060004.99
Something is Killing Child 00001BOOM! Studios 2019-09-040003.99
Department of Truth 00001Image Comics 2020-09-300003.99
Nice House on the Lake 00001DC Black Label 2021-06-010003.99
Ultimate Spider-Man 00001Marvel 2024-01-100005.99
Comencemos.
1. Configuración inicial que todo dev de Java odia
Para acelerar la creación de la base, configuré un proyecto usando spring initializr. Básicamente, creé un proyecto Spring Boot con Maven, Java 21 y Spring Boot 4.0.0. Sí, lo creé sin ninguna dependencia, ya que editaré manualmente el pom.xml. Creo que Spring Boot 4.0 ya incluye Spring Batch 6 (si se agrega como dependencia), pero honestamente, hay cosas que prefiero ajustar manualmente.
Con el proyecto creado, construyamos nuestro pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>4.0.0</version>
<relativePath/>
</parent>
<groupId>me.doismiu</groupId>
<artifactId>spring-batch-bean-io</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>spring-batch-bean-io</name>
<description>Spring Batch 6 BeanIO Example</description>
<properties>
<java.version>21</java.version>
<spring-batch.version>6.0.0</spring-batch.version>
<spring-framework.version>7.0.0</spring-framework.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.beanio</groupId>
<artifactId>beanio</artifactId>
<version>2.1.0</version>
<exclusions>
<exclusion>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-core</artifactId>
</exclusion>
<exclusion>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-infrastructure</artifactId>
</exclusion>
<exclusion>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jsr310</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
<pluginRepository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</pluginRepository>
</pluginRepositories>
</project>
Como habrás notado, trabajaremos con las siguientes librerías en este proyecto:
Spring Batch 6.0
Spring Boot 4.0.0
Spring Boot Starter JDBC. Dado que tenemos que configurar el
TransactionManagerpara la conexión a la base de datos, necesitaremos esta librería.BeanIO 2.1.0. ¡La librería que realiza la magia de convertir campos posicionales en atributos de objeto; además, viene con una serie de clases especiales para Spring Batch!
Librerías Jackson para convertir fácilmente el objeto en una estructura JSON en nuestro Writer.
Ahora, crearemos nuestra estructura Main y la conexión a la base de datos. Aquí vemos el primer gran cambio en Spring Batch 6: la llamada "Infraestructura de batch sin recursos por defecto". Cualquiera que haya trabajado con Spring Batch sabe que casi siempre era necesario vincular el Batch a una base de datos, ya que esta tecnología almacena metadatos de ejecuciones de Job y Step, que son de extrema importancia para el control de ejecución. Sin embargo, en la última versión, Batch no necesita vincularse a ninguna base de datos por defecto. Como mencioné, dado que esto es importante, lo configuraremos de todos modos. En nuestro escenario, el batch requiere la estructura de abajo para ejecutarse:
En este proyecto, usé PostgreSQL vía Docker para facilitar las cosas, pero debería funcionar con cualquier base de datos, incluso NoSQL como MongoDB. Para hacer esto, creé el siguiente docker compose.
version: '3.8'
services:
postgres:
image: postgres:15-alpine
container_name: comic_postgres
environment:
POSTGRES_USER: user
POSTGRES_PASSWORD: password
POSTGRES_DB: comicbatch
ports:
- "5432:5432"
volumes:
- postgres_data:/var/lib/postgresql/data
volumes:
postgres_data:
Pero como dije, cualquier base de datos servirá. Después de levantar el docker compose, tendremos un contenedor llamado comic_postgres ejecutándose en nuestro Docker local. Con eso, podemos proceder a configurar el archivo application.properties de nuestro proyecto.
spring.application.name=spring-batch-bean-io
spring.datasource.url=jdbc:postgresql://localhost:5432/comicbatch
spring.datasource.username=user
spring.datasource.password=password
spring.datasource.driver-class-name=org.postgresql.Driver
logging.level.org.springframework.jdbc.core=DEBUG
logging.level.org.springframework.transaction=DEBUG
spring.batch.jdbc.initialize-schema=never
Aquí configuré JDBC para no crear tablas al inicializar. TEÓRICAMENTE, Batch debería crear la estructura de metadatos sin problemas, pero admito que he usado extensivamente las versiones 4 y 5 de Spring Batch, y NUNCA creó la estructura correctamente. Esto lleva a errores en tiempo de ejecución de la aplicación, muy probablemente debido a columnas faltantes o tipado incorrecto. Peor aún sería tomar algún script aleatorio de internet y crear las tablas directamente en la base de datos. En cambio, tenemos una solución que lee la estructura correcta proporcionada por la librería misma y la adapta al tipo de base de datos que estamos usando. Así es como se ve nuestra clase Main, implementando esta lógica de base de datos:
package me.doismiu.fixedlength;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.core.io.ClassPathResource;
import org.springframework.jdbc.datasource.init.DataSourceInitializer;
import org.springframework.jdbc.datasource.init.ResourceDatabasePopulator;
import javax.sql.DataSource;
@SpringBootApplication
public class ComicBatchApplication {
public static void main(String[] args) {
System.exit(
SpringApplication.exit(
SpringApplication.run(ComicBatchApplication.class, args)));
}
@Bean
public DataSourceInitializer databaseInitializer(DataSource dataSource) {
ResourceDatabasePopulator populator = new ResourceDatabasePopulator();
populator.addScript(new ClassPathResource("org/springframework/batch/core/schema-postgresql.sql"));
populator.setContinueOnError(true);
DataSourceInitializer initializer = new DataSourceInitializer();
initializer.setDataSource(dataSource);
initializer.setDatabasePopulator(populator);
return initializer;
}
}
Esto asegura que en la primera ejecución del Batch, cree la estructura adecuada esperada por el framework, ya que el archivo de creación es proporcionado por Spring Batch mismo. Nota que también incluí la línea populator.setContinueOnError(true). Esto significa que cada vez que haya un error de estructura SQL, será ignorado, dado que este script se ejecutará con cada ejecución del Batch. Hay formas más elegantes de manejar esto, o incluso podrías eliminar este método después de la primera ejecución si prefieres. Pero para nuestro ejemplo, funciona bien.
Aprovechemos para finalizar la configuración de la base de datos creando una clase vacía, pero con anotaciones especificando la configuración del TransactionManager:
package me.doismiu.fixedlength.config;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.EnableJdbcJobRepository;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.annotation.Isolation;
@Configuration
@EnableBatchProcessing
@EnableJdbcJobRepository(dataSourceRef = "dataSource", transactionManagerRef = "transactionManager", isolationLevelForCreate = Isolation.READ_COMMITTED, tablePrefix = "BATCH_")
public class JDBCJobRepositoryConfig {
}
2. El objeto con anotaciones BeanIO
Para este proyecto, necesitamos crear un modelo llamado Comic que contenga la información de la plantilla posicional que mostré al principio de la publicación. Podemos hacer esto vía XML o vía anotación, es cuestión de gusto personal. En el ejemplo de este proyecto, usaré la versión con anotación, ya que siento que organiza la estructura de una plantilla posicional de manera más simple.
package me.doismiu.fixedlength.model;
import org.beanio.annotation.Field;
import org.beanio.annotation.Record;
import org.beanio.builder.Align;
import java.math.BigDecimal;
import java.time.LocalDate;
@Record
public class Comic {
@Field(at = 0, length = 30, padding = ' ', align = Align.LEFT)
private String title;
@Field(at = 30, length = 5, padding = '0', align = Align.RIGHT)
private int issueNumber;
@Field(at = 35, length = 20, padding = ' ', align = Align.LEFT)
private String publisher;
@Field(at = 55, length = 10, format = "yyyy-MM-dd")
private LocalDate publicationDate;
@Field(at = 65, length = 7, padding = '0', align = Align.RIGHT)
private BigDecimal coverPrice;
// Getters y Setters
}
Respecto al modelo, algunos puntos vale la pena destacar:
Los atributos no necesariamente deben estar en el orden de la plantilla, pero recomiendo encarecidamente mantenerlos así para facilitar el mantenimiento del código.
Usamos la lógica de relleno + alineación para llenar con ceros a la izquierda o espacios a la derecha, según lo estipulado en el layout del archivo. Además, le decimos a BeanIO que el campo de fecha esperado tiene un formato definido. Hablaremos más de esto al escribir el Reader de la aplicación.
Y eso es todo, así de simple. Ahora pasemos a crear nuestro Reader y Writer.
3. Un Reader que justifica la existencia de esta publicación, un Writer que hace lo que diablos quiera
Típicamente, la lógica de Batch dicta crear una aplicación en el siguiente orden: Job -> Step -> Reader/Processor/Writer. Pero dado que cada pieza depende de la anterior, comenzaremos desde el final.
En nuestro Reader, usaremos lo mejor que BeanIO ofrece para Batches. Crearemos nuestra lógica de lectura de archivos usando el StreamBuilder estándar de la librería. También usaremos la propia lógica de Skip de BeanIO para evitar releer entradas de la base de datos al reanudar un servicio que ha sido interrumpido. Para que esto funcione, en lugar de usar el FileFlatItemReader estándar de Batch, usaremos AbstractItemCountingItemStreamItemReader. Esto nos permite reanudar cualquier proceso de lectura que fue interrumpido, combinado con la lógica de JumpItem que creamos con BeanIO. Básicamente, configuraremos el StreamBuilder en el constructor de la clase y manejaremos la apertura y cierre de streams adecuadamente. Esto nos da el siguiente reader:
package me.doismiu.fixedlength.reader;
import me.doismiu.fixedlength.handler.LocalDateTypeHandler;
import me.doismiu.fixedlength.model.Comic;
import org.beanio.BeanReader;
import org.beanio.StreamFactory;
import org.beanio.builder.FixedLengthParserBuilder;
import org.beanio.builder.StreamBuilder;
import org.springframework.batch.infrastructure.item.ItemStreamException;
import org.springframework.batch.infrastructure.item.support.AbstractItemCountingItemStreamItemReader;
import org.springframework.core.io.Resource;
import org.springframework.util.Assert;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
import java.time.LocalDate;
public class ComicItemsReader extends AbstractItemCountingItemStreamItemReader<Comic> {
private final Resource resource;
private final StreamFactory streamFactory;
private BeanReader beanReader;
public ComicItemsReader(Resource resource) {
this.resource = resource;
setName("comicItemsReader");
this.streamFactory = StreamFactory.newInstance();
StreamBuilder builder = new StreamBuilder("comicStream")
.format("fixedlength")
.parser(new FixedLengthParserBuilder())
.addTypeHandler(LocalDate.class, new LocalDateTypeHandler("yyyy-MM-dd"))
.addRecord(Comic.class);
this.streamFactory.define(builder);
}
@Override
protected void jumpToItem(int itemIndex) throws Exception {
if (beanReader != null) {
beanReader.skip(itemIndex);
}
}
@Override
protected void doOpen() throws Exception {
Assert.notNull(resource, "Input resource must be set");
if (!resource.exists()) {
throw new ItemStreamException("Input resource does not exist: " + resource);
}
this.beanReader = streamFactory.createReader(
"comicStream",
new InputStreamReader(resource.getInputStream(), StandardCharsets.UTF_8));
}
@Override
protected Comic doRead() throws Exception {
if (beanReader == null) {
return null;
}
return (Comic) beanReader.read();
}
@Override
protected void doClose() throws Exception {
if (beanReader != null) {
beanReader.close();
beanReader = null;
}
}
}
Nota que al implementar esta clase, el compilador marcará un error en la siguiente línea:
.addTypeHandler(LocalDate.class, new LocalDateTypeHandler("yyyy-MM-dd"))
Esto se debe a que aún no hemos creado el LocalDateTypeHandler. ¿Y por qué necesitamos un manejador específico para fechas? En una aplicación de ejemplo, podría ignorar un atributo LocalDate y manejar todo como Strings e Ints. Pero como dije, uno de los principales tipos de archivos procesados en batches se relaciona con pagos. Y los pagos tienen fechas. Queremos poder manipular este atributo como una fecha. Si ejecutamos el reader sin nuestra lógica TypeHandler, obtendremos el siguiente error:
org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'importComicJob' defined in class path resource [me/doismiu/fixedlength/job/ComicPrinterJob.class]: Unsatisfied dependency expressed through method 'importComicJob' parameter 1: Error creating bean with name 'printStep' defined in class path resource [me/doismiu/fixedlength/step/ComicPrinterStep.class]: Unsatisfied dependency expressed through method 'printStep' parameter 2: Error creating bean with name 'comicItemsReader' defined in class path resource [me/doismiu/fixedlength/step/ComicPrinterStep.class]: Failed to instantiate [me.doismiu.fixedlength.reader.ComicItemsReader]: Factory method 'comicItemsReader' threw exception with message: Invalid field 'publicationDate', in record 'comic', in stream 'comicStream': Type handler not found for type 'java.time.LocalDate'
En resumen: BeanIO no proporciona un TypeHandler por defecto para LocalDate con el formato que queremos. Por eso crearemos una clase para resolver esto.
package me.doismiu.fixedlength.handler;
import org.beanio.types.ConfigurableTypeHandler;
import org.beanio.types.TypeHandler;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.util.Properties;
public class LocalDateTypeHandler implements ConfigurableTypeHandler {
private final DateTimeFormatter formatter;
public LocalDateTypeHandler(String pattern) {
this.formatter = DateTimeFormatter.ofPattern(pattern);
}
@Override
public TypeHandler newInstance(Properties properties) throws IllegalArgumentException {
String format = properties.getProperty("format");
if (format == null || format.isEmpty()) {
return this;
}
return new LocalDateTypeHandler(format);
}
@Override
public Object parse(String text) {
if (text == null || text.trim().isEmpty()) {
return null;
}
return LocalDate.parse(text, formatter);
}
@Override
public String format(Object value) {
if (value == null) {
return null;
}
return ((LocalDate) value).format(formatter);
}
@Override
public Class<?> getType() {
return LocalDate.class;
}
}
Básicamente, estamos registrando nuestro tipo de formato personalizado, así de simple. Ahora finalmente tenemos nuestro LocalDateTypeHandler creado y vinculado a nuestro Reader. Es así de fácil.
Para nuestro Writer, como se especificó, el alcance de este proyecto es solo mostrar la salida del archivo en la consola como JSON para demostrar que estamos usando Objetos reales. Aquí, simplemente implementar ItemWriter es suficiente. Pero puedes hacer lo que quieras con los datos; depende de ti. No me extenderé más en el Writer.
package me.doismiu.fixedlength.writer;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.SerializationFeature;
import com.fasterxml.jackson.datatype.jsr310.JavaTimeModule;
import me.doismiu.fixedlength.model.Comic;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.infrastructure.item.Chunk;
import org.springframework.batch.infrastructure.item.ItemWriter;
import org.springframework.stereotype.Component;
import java.util.List;
@Component
public class ComicPrinterWriter implements ItemWriter<Comic> {
private static final Logger LOGGER = LoggerFactory.getLogger(ComicPrinterWriter.class);
private final ObjectMapper objectMapper;
public ComicPrinterWriter() {
this.objectMapper = new ObjectMapper();
this.objectMapper.registerModule(new JavaTimeModule());
this.objectMapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
this.objectMapper.enable(SerializationFeature.INDENT_OUTPUT);
}
@Override
public void write(Chunk<? extends Comic> chunk) throws Exception {
LOGGER.info("--- Writing Batch of {} items as JSON ---", chunk.size());
List<? extends Comic> items = chunk.getItems();
String jsonOutput = objectMapper.writeValueAsString(items);
System.out.println(jsonOutput);
}
}
4. El Job y Step faltantes para finalizar el proyecto
Con el Reader y Writer creados, generamos el Step que orquestará ambos. Nada complejo aquí, solo un Step estándar con algo de manejo de fallos y donde especificamos el Resource para nuestro archivo TXT. Si estás usando este ejemplo para Producción, el manejo debería ser más específico, así como la lógica para devolver correctamente el código de salida de la aplicación. Pero para nuestro ejemplo, el código de abajo funciona:
package me.doismiu.fixedlength.step;
import me.doismiu.fixedlength.model.Comic;
import me.doismiu.fixedlength.reader.ComicItemsReader;
import me.doismiu.fixedlength.writer.ComicPrinterWriter;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.Step;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.FileSystemResource;
import org.springframework.transaction.PlatformTransactionManager;
@Configuration
public class ComicPrinterStep {
@Value("${input.file.path:data/comics.txt}")
private String inputFilePath;
@Bean
public ComicItemsReader comicItemsReader() {
return new ComicItemsReader(new FileSystemResource(inputFilePath));
}
@Bean
public Step printStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager,
ComicItemsReader reader,
ComicPrinterWriter writer) {
return new StepBuilder("comicPrinterStep", jobRepository)
.<Comic, Comic>chunk(10)
.transactionManager(transactionManager)
.reader(reader)
.writer(writer)
.faultTolerant()
.skipLimit(1)
.skip(IllegalArgumentException.class)
.build();
}
}
Y con eso, hemos creado nuestro Job.
package me.doismiu.fixedlength.job;
import org.springframework.batch.core.configuration.annotation.EnableJdbcJobRepository;
import org.springframework.batch.core.job.Job;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.job.parameters.RunIdIncrementer;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.Step;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.annotation.Isolation;
@Configuration
public class ComicPrinterJob {
@Bean
public Job importComicJob(JobRepository jobRepository, Step printStep) {
return new JobBuilder("importComicJob", jobRepository)
.incrementer(new RunIdIncrementer())
.start(printStep)
.build();
}
}
Y con eso, hemos creado nuestro Job.Con eso, tenemos toda la estructura configurada.
5. Probando lo que hay que probar
Ahora estamos listos para ejecutar nuestra aplicación final.
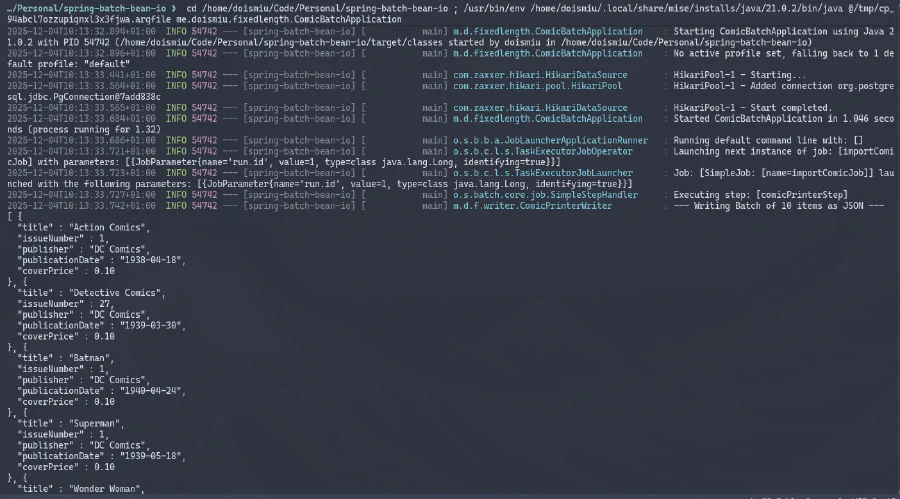
Podemos observar el JSON generado en la consola y la conexión a la base de datos establecida exitosamente. Y dado que creamos una estructura de metadatos para controlar la ejecución, podemos ir directamente a la base de datos para verificar los detalles de ejecución:
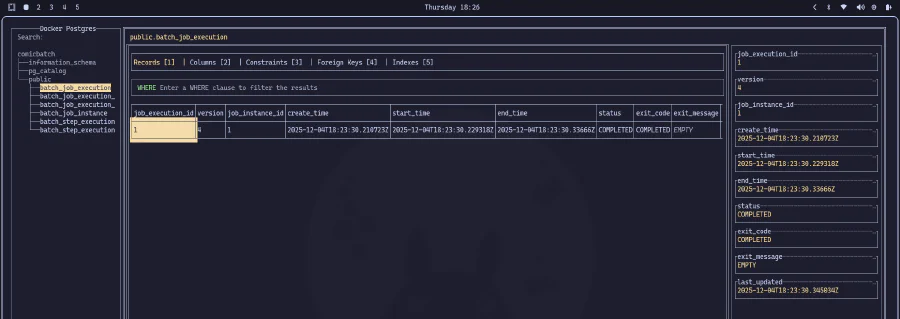
¡GRAN ÉXITO!
6. Conclusión
Con esto, ahora tenemos la lógica básica para leer archivos posicionales de ancho fijo. No es nada complejo, pero dado que este blog pretende ser un respaldo de mi conocimiento, al menos dejo un registro aquí para no olvidarlo de nuevo.

¡Hasta la próxima!
