





Fitxers de Longitud Fixa amb Spring Batch 6.0: La “Alegria” de les Dades Legacy
Si ets un desenvolupador que ha gestionat processament de nòmines o conciliació bancària/financera en una empresa que utilitza Spring, segurament has treballat amb Spring Batch. Confesso que no en sóc un gran fan; té aquella verbositat i sobrecàrrega característica de l’ecosistema Java, fent que fins i tot la feina més simple sembli que requereix molt més estructura de la necessària. Però de què serveix queixar-se? La tecnologia que utilitza la teva empresa és el que assegura la teva supervivència (habitatge, menjar, roba). Així que, queixar-se no és el tema d’avui.
L’abast d’aquesta entrada és extremadament senzill: donat un fitxer posicional generat via un mainframe utilitzant la plantilla següent, crearem una aplicació Spring Batch (utilitzant la versió 6.0, la més recent fins avui) per llegir fàcilment el fitxer, crear un objecte i mostrar el contingut a la consola en format JSON. La part clau aquí és llegir el fitxer i transformar-lo en un objecte Java estàndard. Pel que fa al pas d’escriptura, pots gestionar-ho com vulguis: guardar-lo a una base de dades, escriure a un altre fitxer, el que dimonis vulguis fer.
Per això, considerarem la plantilla següent:
| CAMP | INICI | FI | LONGITUD | FORMAT (COBOL PIC) | TIPUS DE DADES | DESCRIPCIÓ |
|---|---|---|---|---|---|---|
| COMIC-TITLE | 01 | 30 | 30 | PIC X(30) | ALFANUMÈRIC | El títol del còmic. Alineat a l’esquerra, farcit amb espais. |
| ISSUE-NUM | 31 | 35 | 05 | PIC 9(05) | NUMÈRIC (ZONED) | El número de seqüència de la publicació. Alineat a la dreta, farcit amb zeros. |
| PUBLISHER | 36 | 55 | 20 | PIC X(20) | ALFANUMÈRIC | El nom de l’editorial. Alineat a l’esquerra, farcit amb espais. |
| PUB-DATE | 56 | 65 | 10 | PIC X(10) | DATA (ISO) | Data de publicació en format YYYY-MM-DD. Tractat com a text. |
| CVR-PRICE | 66 | 72 | 07 | PIC 9(07) | NUMÈRIC (ZONED) | Preu de portada. Alineat a la dreta, farcit amb zeros. Nota: El maneig decimal depèn de la lògica d’anàlisi. |
I assumim que estem rebent el fitxer següent a la plataforma distribuïda. Tingues en compte que quan tractem amb formats numèrics (PIC 9), omplim el camp amb zeros a l’esquerra, i per als camps alfanumèrics (PIC X), farcim la longitud fixa amb espais a la dreta.
Action Comics 00001DC Comics 1938-04-180000.10
Detective Comics 00027DC Comics 1939-03-300000.10
Batman 00001DC Comics 1940-04-240000.10
Superman 00001DC Comics 1939-05-180000.10
Wonder Woman 00001DC Comics 1942-07-220000.10
Flash Comics 00001DC Comics 1940-01-010000.10
Green Lantern 00001DC Comics 1941-07-010000.10
Amazing Fantasy 00015Marvel 1962-08-100000.12
The Incredible Hulk 00001Marvel 1962-05-010000.12
Fantastic Four 00001Marvel 1961-11-010000.10
Journey into Mystery 00083Marvel 1962-08-010000.12
Tales of Suspense 00039Marvel 1963-03-010000.12
The X-Men 00001Marvel 1963-09-010000.12
The Avengers 00001Marvel 1963-09-010000.12
Daredevil 00001Marvel 1964-04-010000.12
Showcase 00004DC Comics 1956-09-010000.10
Justice League of America 00001DC Comics 1960-10-010000.10
The Brave and the Bold 00028DC Comics 1960-02-010000.10
Swamp Thing 00001DC Comics 1972-10-010000.20
Giant-Size X-Men 00001Marvel 1975-05-010000.50
Crisis on Infinite Earths 00001DC Comics 1985-04-010000.75
Watchmen 00001DC Comics 1986-09-010001.50
The Dark Knight Returns 00001DC Comics 1986-02-010002.95
Maus 00001Pantheon 1986-01-010003.50
Sandman 00001Vertigo 1989-01-010001.50
Spawn 00001Image Comics 1992-05-010001.95
Savage Dragon 00001Image Comics 1992-06-010001.95
WildC.A.T.s 00001Image Comics 1992-08-010001.95
Youngblood 00001Image Comics 1992-04-010002.50
Hellboy: Seed of Destruction 00001Dark Horse 1994-03-010002.50
Sin City 00001Dark Horse 1991-04-010002.25
Preacher 00001Vertigo 1995-04-010002.50
The Walking Dead 00001Image Comics 2003-10-010002.99
Invincible 00001Image Comics 2003-01-010002.99
Saga 00001Image Comics 2012-03-140002.99
Paper Girls 00001Image Comics 2015-10-070002.99
Monstress 00001Image Comics 2015-11-040004.99
Descender 00001Image Comics 2015-03-040002.99
East of West 00001Image Comics 2013-03-270003.50
Ms. Marvel 00001Marvel 2014-02-010002.99
Miles Morales: Spider-Man 00001Marvel 2018-12-120003.99
House of X 00001Marvel 2019-07-240005.99
Powers of X 00001Marvel 2019-07-310005.99
Batman: Court of Owls 00001DC Comics 2011-09-210002.99
Doomsday Clock 00001DC Comics 2017-11-220004.99
Immortal Hulk 00001Marvel 2018-06-060004.99
Something is Killing Child 00001BOOM! Studios 2019-09-040003.99
Department of Truth 00001Image Comics 2020-09-300003.99
Nice House on the Lake 00001DC Black Label 2021-06-010003.99
Ultimate Spider-Man 00001Marvel 2024-01-100005.99
Comencem.
1. Configuració inicial que tots els desenvolupadors Java odien
Per accelerar la creació de la base, vaig configurar un projecte utilitzant spring initializr. Bàsicament, vaig crear un projecte Spring Boot amb Maven, Java 21 i Spring Boot 4.0.0. Sí, el vaig crear sense cap dependència, ja que editaré manualment el pom.xml. Crec que Spring Boot 4.0 ja inclou Spring Batch 6 (si s’afegeix com a dependència), però sincerament, hi ha coses que prefereix ajustar manualment.
Amb el projecte creat, construïm el nostre pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>4.0.0</version>
<relativePath/>
</parent>
<groupId>me.doismiu</groupId>
<artifactId>spring-batch-bean-io</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>spring-batch-bean-io</name>
<description>Spring Batch 6 BeanIO Example</description>
<properties>
<java.version>21</java.version>
<spring-batch.version>6.0.0</spring-batch.version>
<spring-framework.version>7.0.0</spring-framework.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.beanio</groupId>
<artifactId>beanio</artifactId>
<version>2.1.0</version>
<exclusions>
<exclusion>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-core</artifactId>
</exclusion>
<exclusion>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-infrastructure</artifactId>
</exclusion>
<exclusion>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jsr310</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
<pluginRepository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</pluginRepository>
</pluginRepositories>
</project>
Com pots haver notat, treballarem amb les següents llibreries en aquest projecte:
Spring Batch 6.0
Spring Boot 4.0.0
Spring Boot Starter JDBC. Com que hem de configurar el
TransactionManagerper a la connexió a la base de dades, necessitarem aquesta llibreria.BeanIO 2.1.0. La llibreria que fa la màgia de convertir camps posicionals en atributs d’objecte; a més, ve amb una sèrie de classes especials per a Spring Batch!
Llibreries Jackson per convertir fàcilment l’objecte en una estructura JSON al nostre Writer.
Ara, crearem la nostra estructura Main i la connexió a la base de dades. Aquí veiem el primer gran canvi a Spring Batch 6: l’anomenada "Infraestructura de batch sense recursos per defecte". Qualsevol que hagi treballat amb Spring Batch sap que gairebé sempre era necessari vincular el Batch a una base de dades, ja que aquesta tecnologia emmagatzema metadades per a les execucions de Job i Step, que són d’extrema importància per al control d’execució. No obstant això, en l’última versió, Batch no necessita estar vinculat a cap base de dades per defecte. Com he mencionat, com que això és important, ho configurarem igualment. En el nostre escenari, el batch requereix l’estructura següent per executar-se:
En aquest projecte, vaig utilitzar PostgreSQL via Docker per fer les coses més fàcils, però hauria de funcionar amb qualsevol base de dades, fins i tot NoSQL com MongoDB. Per fer-ho, vaig crear el següent docker compose.
version: '3.8'
services:
postgres:
image: postgres:15-alpine
container_name: comic_postgres
environment:
POSTGRES_USER: user
POSTGRES_PASSWORD: password
POSTGRES_DB: comicbatch
ports:
- "5432:5432"
volumes:
- postgres_data:/var/lib/postgresql/data
volumes:
postgres_data:
Però com he dit, qualsevol base de dades servirà. Després d’iniciar el docker compose, tindrem un contenidor anomenat comic_postgres executant-se al nostre Docker local. Amb això, podem procedir a configurar el fitxer application.properties del nostre projecte.
spring.application.name=spring-batch-bean-io
spring.datasource.url=jdbc:postgresql://localhost:5432/comicbatch
spring.datasource.username=user
spring.datasource.password=password
spring.datasource.driver-class-name=org.postgresql.Driver
logging.level.org.springframework.jdbc.core=DEBUG
logging.level.org.springframework.transaction=DEBUG
spring.batch.jdbc.initialize-schema=never
Aquí he configurat JDBC per no crear taules en la inicialització. TEÒRICAMENT, Batch hauria de crear l’estructura de metadades sense cap problema, però admeto que he utilitzat àmpliament les versions 4 i 5 de Spring Batch, i MAI va crear l’estructura correctament. Això condueix a errors d’execució de l’aplicació, molt probablement a causa de columnes faltants o tipificació incorrecta. Pitjor encara seria agafar algun script aleatori d’Internet i crear les taules directament a la base de dades. En canvi, tenim una solució que llegeix l’estructura correcta proporcionada per la pròpia llibreria i l’adapta al tipus de base de dades que estem utilitzant. Així és com es veu la nostra classe Main, implementant aquesta lògica de base de dades:
package me.doismiu.fixedlength;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.core.io.ClassPathResource;
import org.springframework.jdbc.datasource.init.DataSourceInitializer;
import org.springframework.jdbc.datasource.init.ResourceDatabasePopulator;
import javax.sql.DataSource;
@SpringBootApplication
public class ComicBatchApplication {
public static void main(String[] args) {
System.exit(
SpringApplication.exit(
SpringApplication.run(ComicBatchApplication.class, args)));
}
@Bean
public DataSourceInitializer databaseInitializer(DataSource dataSource) {
ResourceDatabasePopulator populator = new ResourceDatabasePopulator();
populator.addScript(new ClassPathResource("org/springframework/batch/core/schema-postgresql.sql"));
populator.setContinueOnError(true);
DataSourceInitializer initializer = new DataSourceInitializer();
initializer.setDataSource(dataSource);
initializer.setDatabasePopulator(populator);
return initializer;
}
}
Això assegura que en la primera execució del Batch, es crea l’estructura adequada esperada pel framework, ja que el fitxer de creació és proporcionat pel propi Spring Batch. Tingues en compte que també he inclòs la línia populator.setContinueOnError(true). Això significa que sempre que hi hagi un error d’estructura SQL, serà ignorat, donat que aquest script s’executarà amb cada execució del Batch. Hi ha maneres més elegants de gestionar això, o fins i tot podries eliminar aquest mètode després de la primera execució si ho prefereixes. Però per al nostre exemple, funciona bé.
Aprofitem per finalitzar la configuració de la base de dades creant una classe buida, però amb anotacions especificant la configuració del TransactionManager:
package me.doismiu.fixedlength.config;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.EnableJdbcJobRepository;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.annotation.Isolation;
@Configuration
@EnableBatchProcessing
@EnableJdbcJobRepository(dataSourceRef = "dataSource", transactionManagerRef = "transactionManager", isolationLevelForCreate = Isolation.READ_COMMITTED, tablePrefix = "BATCH_")
public class JDBCJobRepositoryConfig {
}
2. L’objecte amb anotacions BeanIO
Per a aquest projecte, necessitem crear un model anomenat Comic que contingui la informació de la plantilla posicional que vaig mostrar al principi de l’entrada. Podem fer-ho via XML o via anotació, és qüestió de gust personal. En l’exemple d’aquest projecte, utilitzaré la versió d’anotació, ja que sento que organitza l’estructura d’una plantilla posicional de manera més senzilla.
package me.doismiu.fixedlength.model;
import org.beanio.annotation.Field;
import org.beanio.annotation.Record;
import org.beanio.builder.Align;
import java.math.BigDecimal;
import java.time.LocalDate;
@Record
public class Comic {
@Field(at = 0, length = 30, padding = ' ', align = Align.LEFT)
private String title;
@Field(at = 30, length = 5, padding = '0', align = Align.RIGHT)
private int issueNumber;
@Field(at = 35, length = 20, padding = ' ', align = Align.LEFT)
private String publisher;
@Field(at = 55, length = 10, format = "yyyy-MM-dd")
private LocalDate publicationDate;
@Field(at = 65, length = 7, padding = '0', align = Align.RIGHT)
private BigDecimal coverPrice;
// Getters and Setters
}
Pel que fa al model, alguns punts val la pena destacar:
Els atributs no necessàriament han d’estar en l’ordre de la plantilla, però recomano encaridament mantenir-los així per facilitar el manteniment del codi.
Utilitzem la lògica padding + align per omplir amb zeros a l’esquerra o espais a la dreta, com s’estipula a la disposició del fitxer. A més, indiquem a BeanIO que el camp de data esperat té un format definit. Parlarem més d’això en escriure el Reader de l’aplicació.
I això és tot, tan senzill com això. Ara passem a crear el nostre Reader i Writer.
3. Un Reader que justifica l’existència d’aquesta entrada, un Writer que fa el que dimonis vulgui
Normalment, la lògica del Batch dicta crear una aplicació en l’ordre següent: Job -> Step -> Reader/Processor/Writer. Però com que cada peça depèn de l’anterior, començarem pel final.
En el nostre Reader, utilitzarem el millor que BeanIO ofereix per als Batches. Crearem la nostra lògica de lectura de fitxers utilitzant el StreamBuilder estàndard de la llibreria. També utilitzarem la pròpia lògica Skip de BeanIO per evitar tornar a llegir entrades de la base de dades en reprendre un servei que ha estat interromput. Perquè això funcioni, en lloc d’utilitzar el FileFlatItemReader estàndard del Batch, utilitzarem AbstractItemCountingItemStreamItemReader. Això ens permet reprendre qualsevol procés de lectura que hagi estat interromput, combinat amb la lògica JumpItem que creem amb BeanIO. Bàsicament, configurarem el StreamBuilder al constructor de la classe i gestionarem l’obertura i el tancament de fluxos adequadament. Això ens dóna el següent lector:
package me.doismiu.fixedlength.reader;
import me.doismiu.fixedlength.handler.LocalDateTypeHandler;
import me.doismiu.fixedlength.model.Comic;
import org.beanio.BeanReader;
import org.beanio.StreamFactory;
import org.beanio.builder.FixedLengthParserBuilder;
import org.beanio.builder.StreamBuilder;
import org.springframework.batch.infrastructure.item.ItemStreamException;
import org.springframework.batch.infrastructure.item.support.AbstractItemCountingItemStreamItemReader;
import org.springframework.core.io.Resource;
import org.springframework.util.Assert;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
import java.time.LocalDate;
public class ComicItemsReader extends AbstractItemCountingItemStreamItemReader<Comic> {
private final Resource resource;
private final StreamFactory streamFactory;
private BeanReader beanReader;
public ComicItemsReader(Resource resource) {
this.resource = resource;
setName("comicItemsReader");
this.streamFactory = StreamFactory.newInstance();
StreamBuilder builder = new StreamBuilder("comicStream")
.format("fixedlength")
.parser(new FixedLengthParserBuilder())
.addTypeHandler(LocalDate.class, new LocalDateTypeHandler("yyyy-MM-dd"))
.addRecord(Comic.class);
this.streamFactory.define(builder);
}
@Override
protected void jumpToItem(int itemIndex) throws Exception {
if (beanReader != null) {
beanReader.skip(itemIndex);
}
}
@Override
protected void doOpen() throws Exception {
Assert.notNull(resource, "Input resource must be set");
if (!resource.exists()) {
throw new ItemStreamException("Input resource does not exist: " + resource);
}
this.beanReader = streamFactory.createReader(
"comicStream",
new InputStreamReader(resource.getInputStream(), StandardCharsets.UTF_8));
}
@Override
protected Comic doRead() throws Exception {
if (beanReader == null) {
return null;
}
return (Comic) beanReader.read();
}
@Override
protected void doClose() throws Exception {
if (beanReader != null) {
beanReader.close();
beanReader = null;
}
}
}
Tingues en compte que en implementar aquesta classe, el compilador assenyalarà un error a la línia següent:
.addTypeHandler(LocalDate.class, new LocalDateTypeHandler("yyyy-MM-dd"))
Això és perquè encara no hem creat el LocalDateTypeHandler. I per què necessitem un gestor específic per a dates? En una aplicació d’exemple, podria ignorar un atribut LocalDate i gestionar-ho tot com a Strings i Ints. Però com he dit, un dels principals tipus de fitxers processats en batches està relacionat amb pagaments. I els pagaments tenen dates. Volem poder manipular aquest atribut com una data. Si executem el lector sense la nostra lògica TypeHandler, obtindrem el següent error:
org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'importComicJob' defined in class path resource [me/doismiu/fixedlength/job/ComicPrinterJob.class]: Unsatisfied dependency expressed through method 'importComicJob' parameter 1: Error creating bean with name 'printStep' defined in class path resource [me/doismiu/fixedlength/step/ComicPrinterStep.class]: Unsatisfied dependency expressed through method 'printStep' parameter 2: Error creating bean with name 'comicItemsReader' defined in class path resource [me/doismiu/fixedlength/step/ComicPrinterStep.class]: Failed to instantiate [me.doismiu.fixedlength.reader.ComicItemsReader]: Factory method 'comicItemsReader' threw exception with message: Invalid field 'publicationDate', in record 'comic', in stream 'comicStream': Type handler not found for type 'java.time.LocalDate'
En resum: BeanIO no proporciona un TypeHandler per defecte per a LocalDate amb el format que volem. Per això crearem una classe per solucionar això.
package me.doismiu.fixedlength.handler;
import org.beanio.types.ConfigurableTypeHandler;
import org.beanio.types.TypeHandler;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.util.Properties;
public class LocalDateTypeHandler implements ConfigurableTypeHandler {
private final DateTimeFormatter formatter;
public LocalDateTypeHandler(String pattern) {
this.formatter = DateTimeFormatter.ofPattern(pattern);
}
@Override
public TypeHandler newInstance(Properties properties) throws IllegalArgumentException {
String format = properties.getProperty("format");
if (format == null || format.isEmpty()) {
return this;
}
return new LocalDateTypeHandler(format);
}
@Override
public Object parse(String text) {
if (text == null || text.trim().isEmpty()) {
return null;
}
return LocalDate.parse(text, formatter);
}
@Override
public String format(Object value) {
if (value == null) {
return null;
}
return ((LocalDate) value).format(formatter);
}
@Override
public Class<?> getType() {
return LocalDate.class;
}
}
Bàsicament, estem registrant el nostre tipus de format personalitzat, tan senzill com això. Ara finalment tenim el nostre LocalDateTypeHandler creat i vinculat al nostre Reader. És així de fàcil.
Per al nostre Writer, com s’ha especificat, l’abast d’aquest projecte és només mostrar la sortida del fitxer a la consola com a JSON per demostrar que estem utilitzant Objectes reals. Aquí, simplement implementar ItemWriter és suficient. Però pots fer el que vulguis amb les dades; depèn de tu. No m’extendré més en el Writer.
package me.doismiu.fixedlength.writer;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.SerializationFeature;
import com.fasterxml.jackson.datatype.jsr310.JavaTimeModule;
import me.doismiu.fixedlength.model.Comic;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.infrastructure.item.Chunk;
import org.springframework.batch.infrastructure.item.ItemWriter;
import org.springframework.stereotype.Component;
import java.util.List;
@Component
public class ComicPrinterWriter implements ItemWriter<Comic> {
private static final Logger LOGGER = LoggerFactory.getLogger(ComicPrinterWriter.class);
private final ObjectMapper objectMapper;
public ComicPrinterWriter() {
this.objectMapper = new ObjectMapper();
this.objectMapper.registerModule(new JavaTimeModule());
this.objectMapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
this.objectMapper.enable(SerializationFeature.INDENT_OUTPUT);
}
@Override
public void write(Chunk<? extends Comic> chunk) throws Exception {
LOGGER.info("--- Writing Batch of {} items as JSON ---", chunk.size());
List<? extends Comic> items = chunk.getItems();
String jsonOutput = objectMapper.writeValueAsString(items);
System.out.println(jsonOutput);
}
}
4. El Job i Step que falten per finalitzar el projecte
Amb el Reader i Writer creats, generem el Step que orquestrarà tots dos. Res complex aquí, només un Step estàndard amb algun maneig de fallades i on especifiquem el Recurs per al nostre fitxer TXT. Si estàs utilitzant aquest exemple per a Producció, el maneig hauria de ser més específic, així com la lògica per retornar correctament el codi de sortida de l’aplicació. Però per al nostre exemple, el codi següent funciona:
package me.doismiu.fixedlength.step;
import me.doismiu.fixedlength.model.Comic;
import me.doismiu.fixedlength.reader.ComicItemsReader;
import me.doismiu.fixedlength.writer.ComicPrinterWriter;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.Step;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.FileSystemResource;
import org.springframework.transaction.PlatformTransactionManager;
@Configuration
public class ComicPrinterStep {
@Value("${input.file.path:data/comics.txt}")
private String inputFilePath;
@Bean
public ComicItemsReader comicItemsReader() {
return new ComicItemsReader(new FileSystemResource(inputFilePath));
}
@Bean
public Step printStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager,
ComicItemsReader reader,
ComicPrinterWriter writer) {
return new StepBuilder("comicPrinterStep", jobRepository)
.<Comic, Comic>chunk(10)
.transactionManager(transactionManager)
.reader(reader)
.writer(writer)
.faultTolerant()
.skipLimit(1)
.skip(IllegalArgumentException.class)
.build();
}
}
I amb això, hem creat el nostre Job.
package me.doismiu.fixedlength.job;
import org.springframework.batch.core.configuration.annotation.EnableJdbcJobRepository;
import org.springframework.batch.core.job.Job;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.job.parameters.RunIdIncrementer;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.Step;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.annotation.Isolation;
@Configuration
public class ComicPrinterJob {
@Bean
public Job importComicJob(JobRepository jobRepository, Step printStep) {
return new JobBuilder("importComicJob", jobRepository)
.incrementer(new RunIdIncrementer())
.start(printStep)
.build();
}
}
I amb això, hem creat el nostre Job.Amb això, tenim tota l’estructura configurada.
5. Provar el que cal provar
Ara estem preparats per executar la nostra aplicació final.
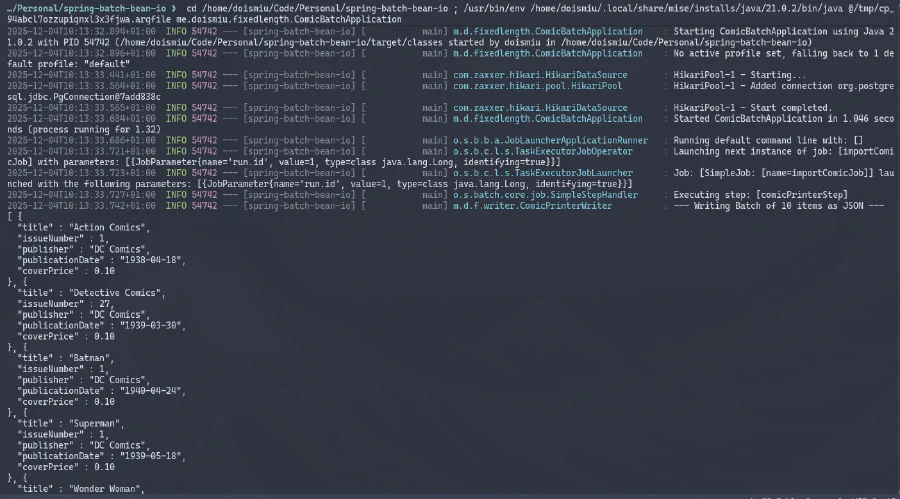
Podem observar el JSON generat a la consola i la connexió a la base de dades establerta amb èxit. I com que vam crear una estructura de metadades per controlar l’execució, podem anar directament a la base de dades per comprovar els detalls de l’execució:
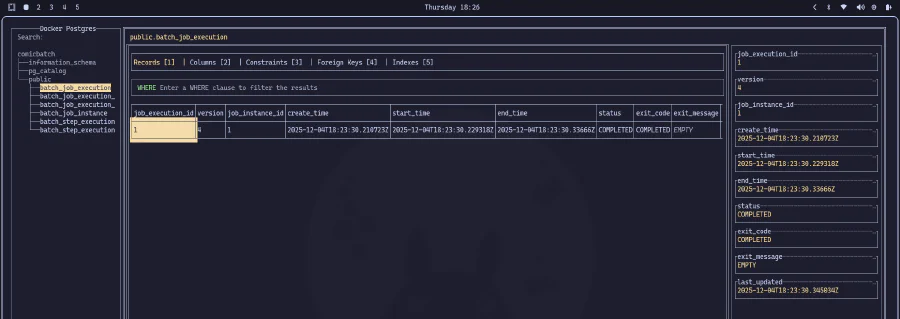
GRAN ÈXIT!
6. Conclusió
Amb això, ara tenim la lògica bàsica per llegir fitxers posicionals d’amplada fixa. No és res complex, però com que aquest bloc pretén ser una còpia de seguretat del meu coneixement, almenys deixo un registre aquí per no oblidar-ho de nou.

Fins a la propera!
